Graph Compilers are just getting started!
The GNU C Compiler – GCC – was first released in 1987. 36 years ago. Several version streams are still actively being developed and enhanced, with GCC13 being the most advanced, and a GCC v10.5 released in early July this year.
You might think that with 36 years of refinement by thousands of contributors that penultimate performance has been achieved. All that could be discovered has been discovered? You’d be wrong. As chart A (source: openbenchmarking.org) shows, incremental performance is still being squeezed out of GCC despite it being old enough to be a grandparent. The geometric mean improvement on the set of 70 benchmarks from Phoronix is 0.2% over the preceding version, and a full 1.6% compared to GCC 5.5 from 2017 – which came 30 full years after the initial release. 36 years after the birth of GCC and still there are meaningful gains to be had.

Figure A: GCC Performance Benchmarks
Gains in GCC are no longer coming in leaps and bounds. But gains are still coming. The asymptote of “perfectly generated code” will likely always be just out of reach.
Graph Compiler Infancy
Compared to the mature 36-year-old GCC, the TVM compiler project – an open-source graph compiler project managed by the Apache software foundation – is in its infancy. First described in a 2017 research paper from University of Washington researchers, the TVM project was adopted by the Apache foundation in 2020 and has gained notable traction in the machine learning inference world.
Quadric’s Chimera Graph Compiler (CGC) is based in-part on TVM and has been heavily extended to optimize for the Chimera architecture. CGC is less than a full 1 year old since Beta deliveries to Quadric customers began in late 2022. CGC is therefore very, very early in the compiler maturity curve, as suggested by Figure B.
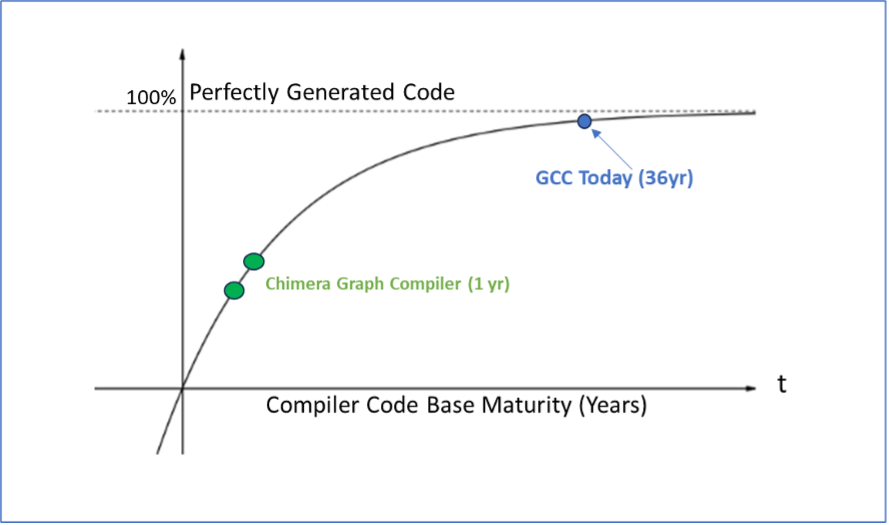
Figure B: Quadric’s Graph Compiler is only just beginning to shine.
Big Leaps in Performance
Unlike fixed-function CNN accelerators deployed in many conventional SoCs today, the Quadric Chimera GPNPU is driven by compiled code. C++ code is generated from Machine Learning (ML) graphs by the CGC graph compiler and by human programmers, then compiled by the LLVM compiler to create the executable binary running on the Chimera core.
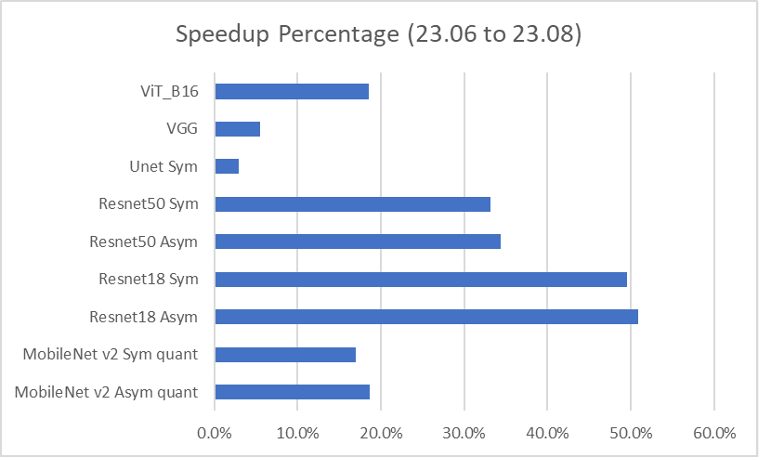
With each new major release of CGC we are seeing big steps improvements in total performance. How big? This chart shows the detailed performance improvements that Quadric delivered from the June 2023 release to the latest August 2023 release:
The most recent CGC update delivered over 50% improvement on one of the common Resnet18 benchmarks, and even a 17% performance improvement on the Vision Transformer (ViT_B). While most fixed-function NN accelerators cannot run Vision Transformers at all, Quadric not only runs transformers, but is poised to continue to deliver large increases in performance – without hardware changes - as the CGC to LLVM compiler stack continues to mature and improve.
35 More Years of Improvement?
Will 17-50% boosts in performance happen with every quarterly incremental release? Perhaps not that extreme, but we are also nowhere near the end of the curve. New optimizations. New re-orderings. Smarter memory layout of tensors. More refined prefetching. Multi-tiered fusions. And more still to come.
Can your fixed-function convolution accelerator be tweaked as knowledge of algorithms grows? No. Can you easily add new graph operators to a finite state machine hard-wired in all layer silicon? No. With a conventional accelerator the functionality is frozen the minute the mask set is created – so you’d better hope that you found those 36 years’ worth of optimizations before paying for that mask set.
© Copyright 2024 Quadric All Rights Reserved Privacy Policy