The biggest mistake a chip design team can make in evaluating AI acceleration options for a new SoC is to rely entirely upon spreadsheets of performance numbers from the NPU vendor without going through the […]
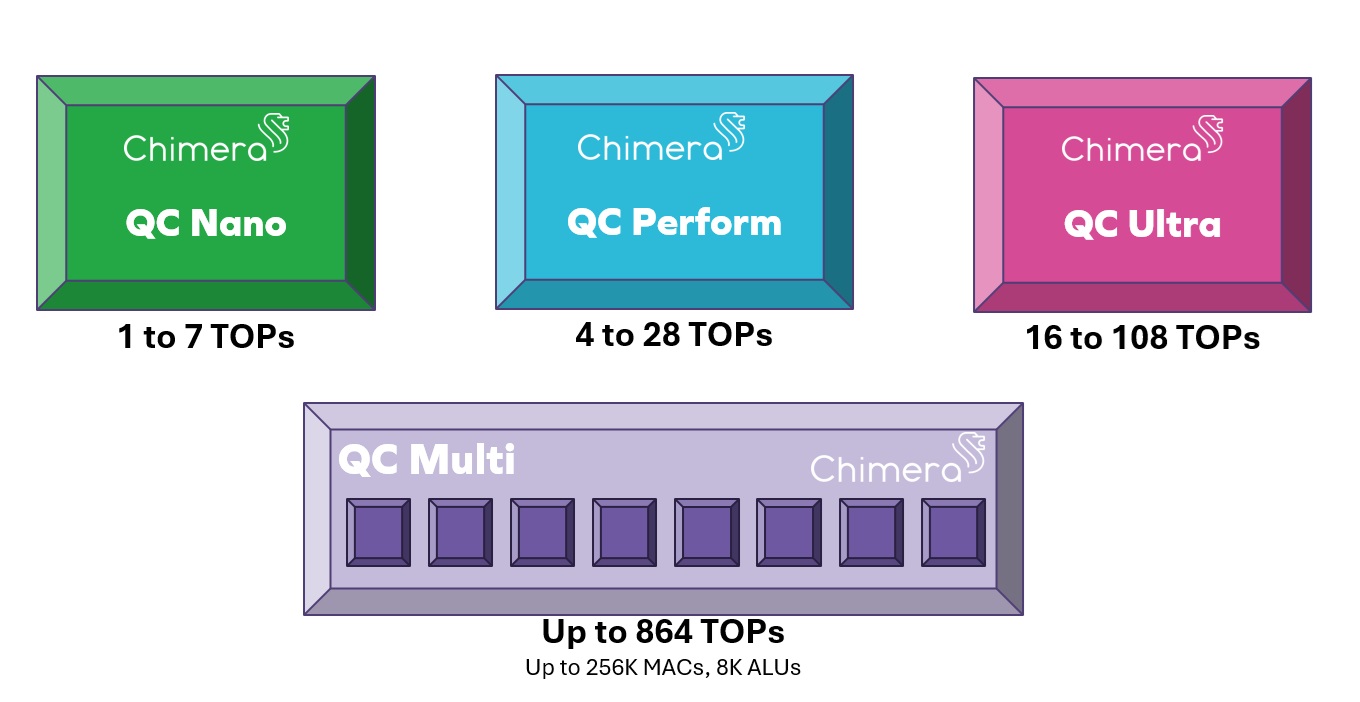
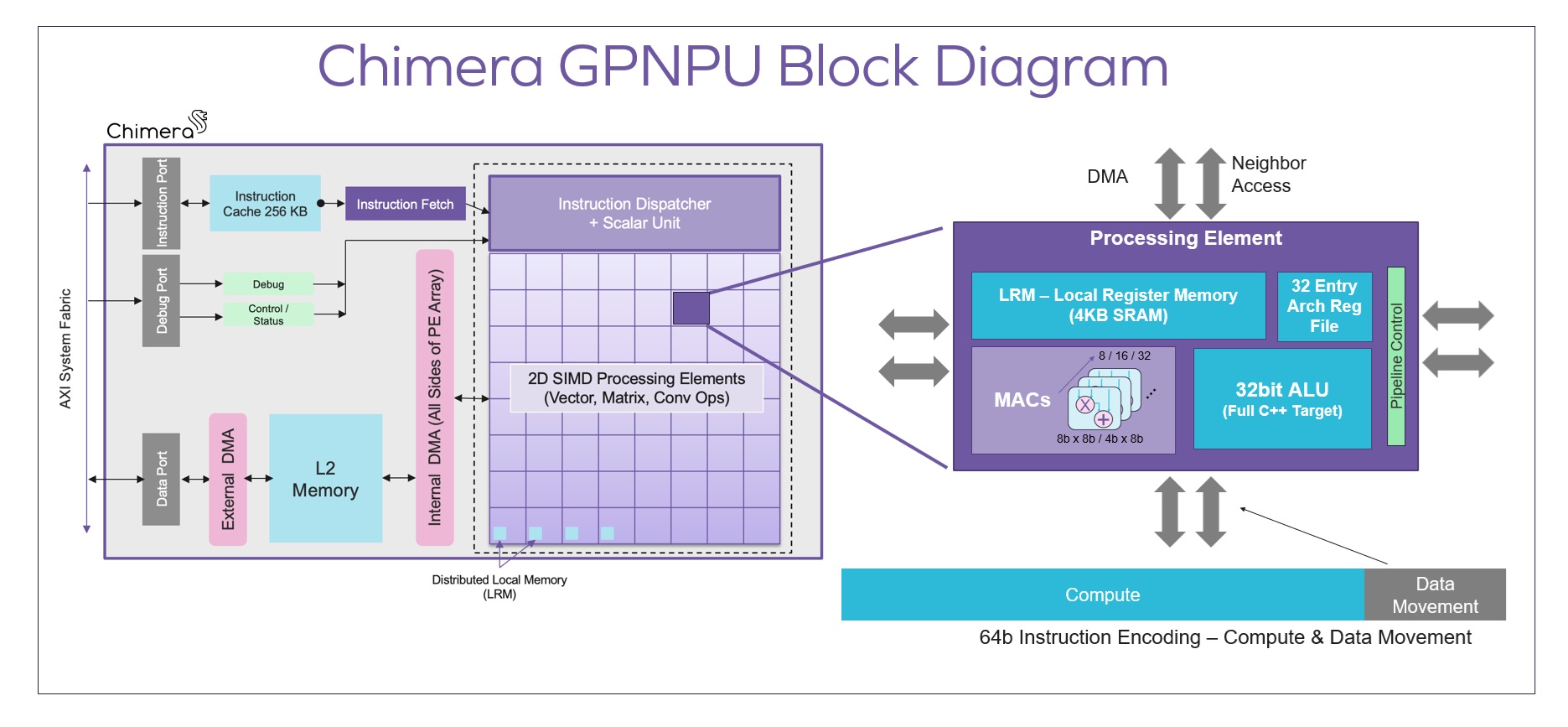
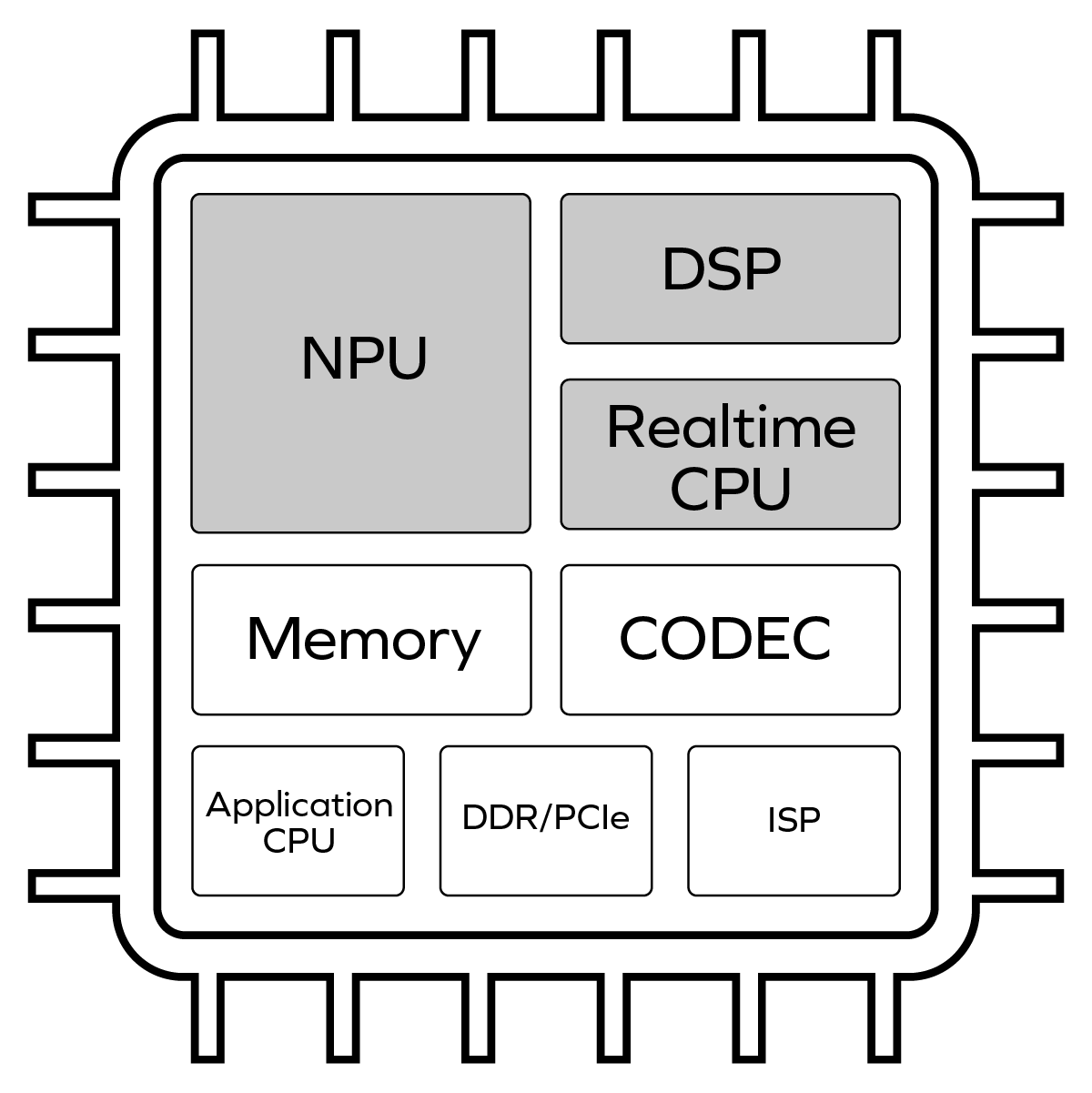
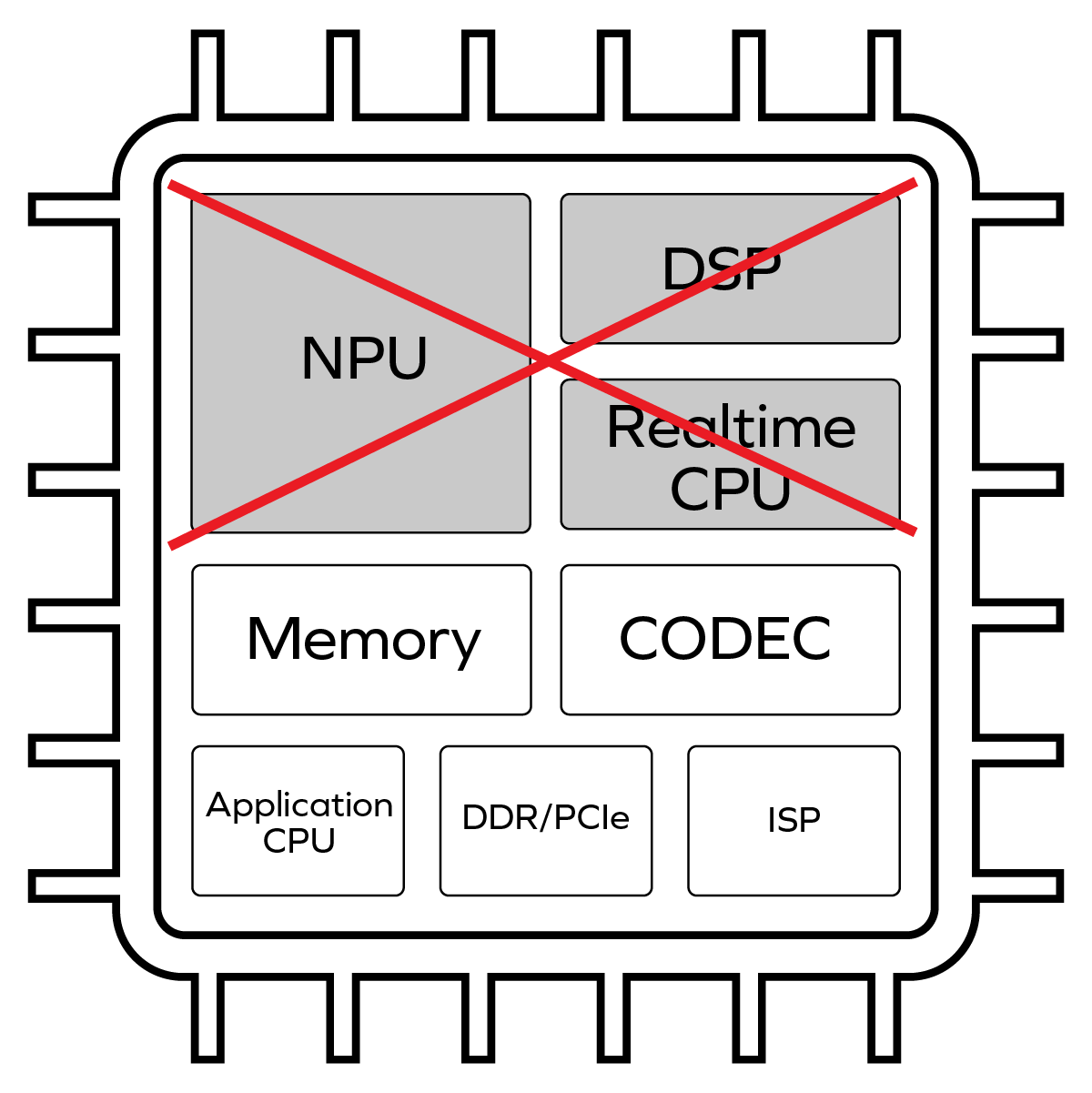
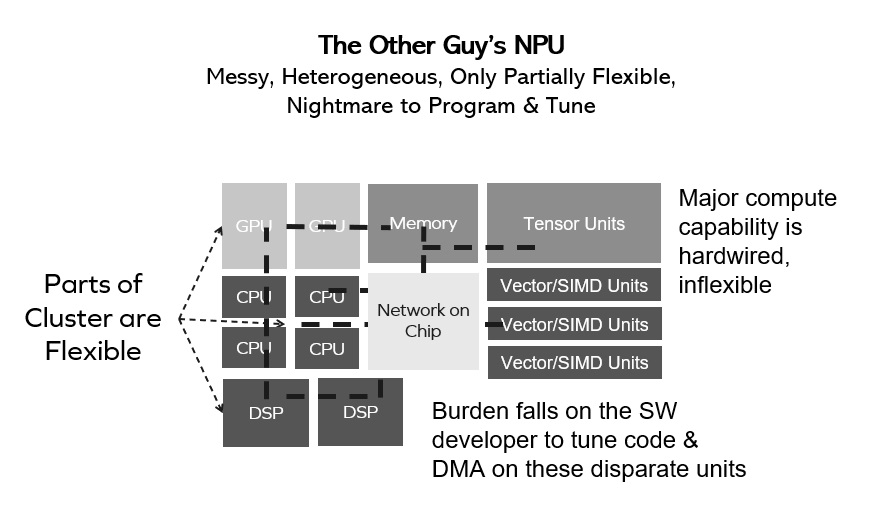
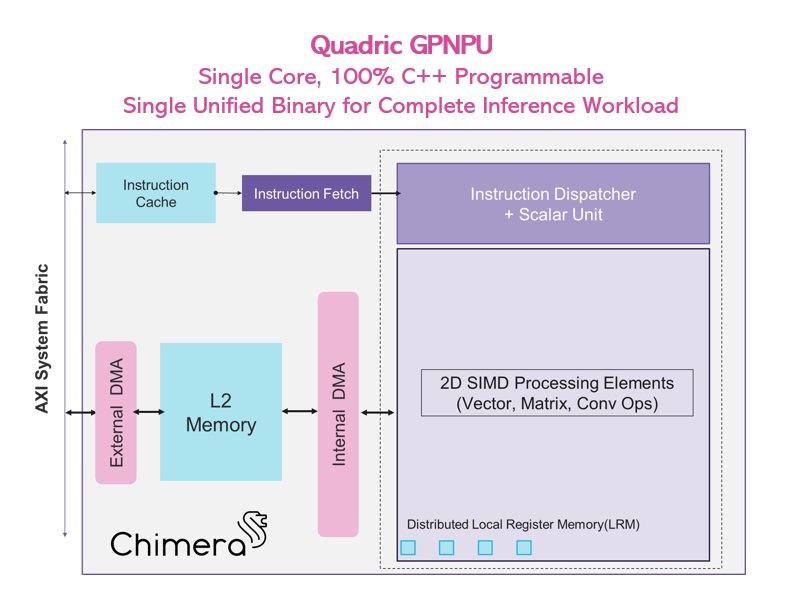
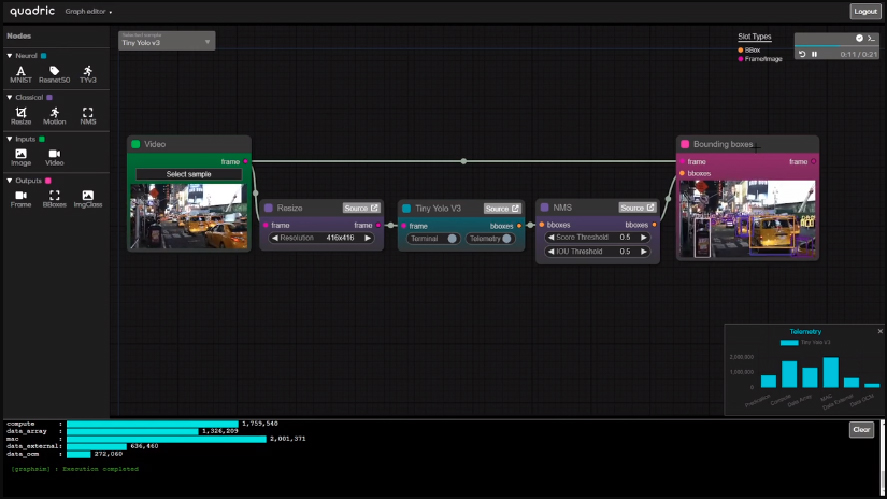
The biggest mistake a chip design team can make in evaluating AI acceleration options for a new SoC is to rely entirely upon spreadsheets of performance numbers from the NPU vendor without going through the […]
On Chimera QC Ultra it runs 28x faster than DSP+NPU ConvNext is one of today’s leading new ML networks. Frankly, it just doesn’t run on most NPUs. So if your AI/ML solution relies on an […]
What’s the biggest challenge for AI/ML? Power consumption. How are we going to meet it? In late April 2024, a novel AI research paper was published by researchers from MIT and CalTech proposing a fundamentally […]
The biggest mistake a chip design team can make in evaluating AI acceleration options for a new SoC is to rely entirely upon spreadsheets of performance numbers from the NPU vendor without going through the […]
On Chimera QC Ultra it runs 28x faster than DSP+NPU ConvNext is one of today’s leading new ML networks. Frankly, it just doesn’t run on most NPUs. So if your AI/ML solution relies on an […]
© Copyright 2024 Quadric All Rights Reserved Privacy Policy