Designed from the ground up to address significant machine learning (ML) inference deployment challenges facing system on chip (SoC) developers, Quadric's Chimera(TM) general purpose neural processor (GPNPU) family has a simple yet powerful architecture with demonstrated improved matrix-computation performance over the traditional approach. Its crucial differentiation is its ability to execute diverse workloads with great flexibility all in a single processor.
The Chimera GPNPU family provides a unified processor architecture that can handle matrix and vector operations and scalar (control) code in one execution pipeline. In conventional SoC architectures these workloads are traditionally handled separately by an NPU, DSP, and realtime CPU, requiring splitting code and tuning performance across two or three heterogenous cores. The Chimera GPNPU is a single software-controlled core, allowing for simple expression of complex parallel workloads.
The Chimera GPNPU is entirely driven by code, empowering developers to continuously optimize the performance of their models and algorithms throughout the device’s lifecycle. That's why it's ideal to run classic backbone networks, todays' newest Vision Transformers and Large Language Models, and whatever new networks are invented tomorrow.
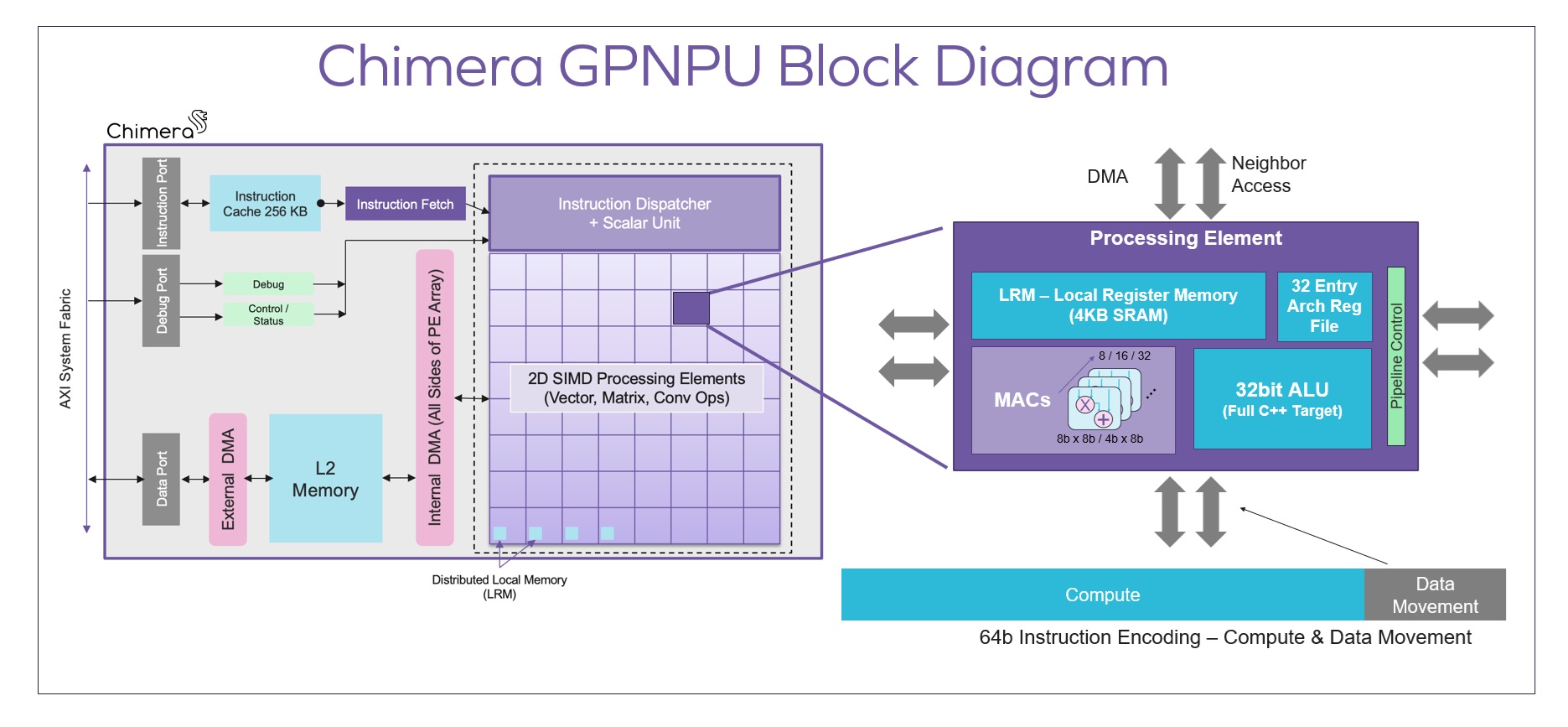
Chimera GPNPU Block Diagram
Modern System-on-Chip (SoC) architectures deploy complex algorithms that mix traditional C++ based code with newly emerging and fast-changing machine learning (ML) inference code. This combination of graph code commingled with C++ code is found in numerous chip subsystems, most prominently in vision and imaging subsystems, radar and lidar processing, communications baseband subsystems, and a variety of other data- rich processing pipelines. Only Quadric’s Chimera GPNPU architecture can deliver high ML inference performance and run complex, data-parallel C++ code on the same fully programmable processor.
Compared to other ML inference architectures that force the software developer to artificially partition an algorithm solution between two or three different kinds of processors, Quadric’s Chimera processors deliver a massive uplift in software developer productivity while also providing current-day graph processing efficiency coupled with long-term future-proof flexibility.
Quadric’s Chimera GPNPUs are licensable processor IP cores delivered in synthesizable source RTL form. Blending the best attributes of both neural processing units (NPUs) and digital signal processors (DSPs), Chimera GPNPUs are aimed at inference applications in a variety of high-volume end applications including mobile devices, digital home applications, automotive and network edge compute systems.
BENEFITS OF A GPNPU
System Simplicity
Quadric’s solution enables hardware developers to instantiate a single core that can handle an entire ML workload plus the typical digital signal processor functions and signal conditioning workloads often intermixed with ML inference functions. Dealing with a single core drastically simplifies hardware integration and eases performance optimization. System design tasks such as profiling memory usage and estimating system power consumption are greatly simplified.
Programming Simplicity
Quadric’s Chimera GPNPU architecture dramatically simplifies software development since matrix, vector, and control code can all be handled in a single code stream. ML graph code from the common training toolsets (Tensorflow, Pytorch, ONNX formats) is compiled by the Quadric SDK and can be merged with signal processing code written in C++, all compiled into a single code stream running on a single processor core.
Quadric’s SDK meets the demands of both hardware and software developers, who no longer need to master multiple toolsets from multiple vendors. The entire subsystem can be debugged in a single debug console. This can dramatically reduce code development time and ease performance optimization.
This new programming paradigm also benefits the end users of the SoCs since they will have access to program all the GPNPU resources.
Future Proof Flexibility
A Chimera GPNPU can run any ML graph that can be captured in ONNX, and anything written in C++. This is incredibly powerful since SoC developers can quickly write code to implement new neural network operators and libraries long after the SoC has been taped out. This eliminates fear of the unknown and dramatically increases a chip’s useful life.
This flexibility is extended to the end users of the SoCs. They can continuously add new features to the end products, giving them a competitive edge.
Replacing a legacy heterogenous ML subsystem comprised of separate NPU, DSP, and realtime CPU cores with one GPNPU has obvious advantages. By allowing vector, matrix, and control code to be handled in a single code stream, the development and debug process is greatly simplified while the ability to add new algorithms efficiently is greatly enhanced.
As ML models continue to evolve and inferencing becomes prevalent in even more applications, the payoff from this unified architecture helps future-proof chip design cycles.
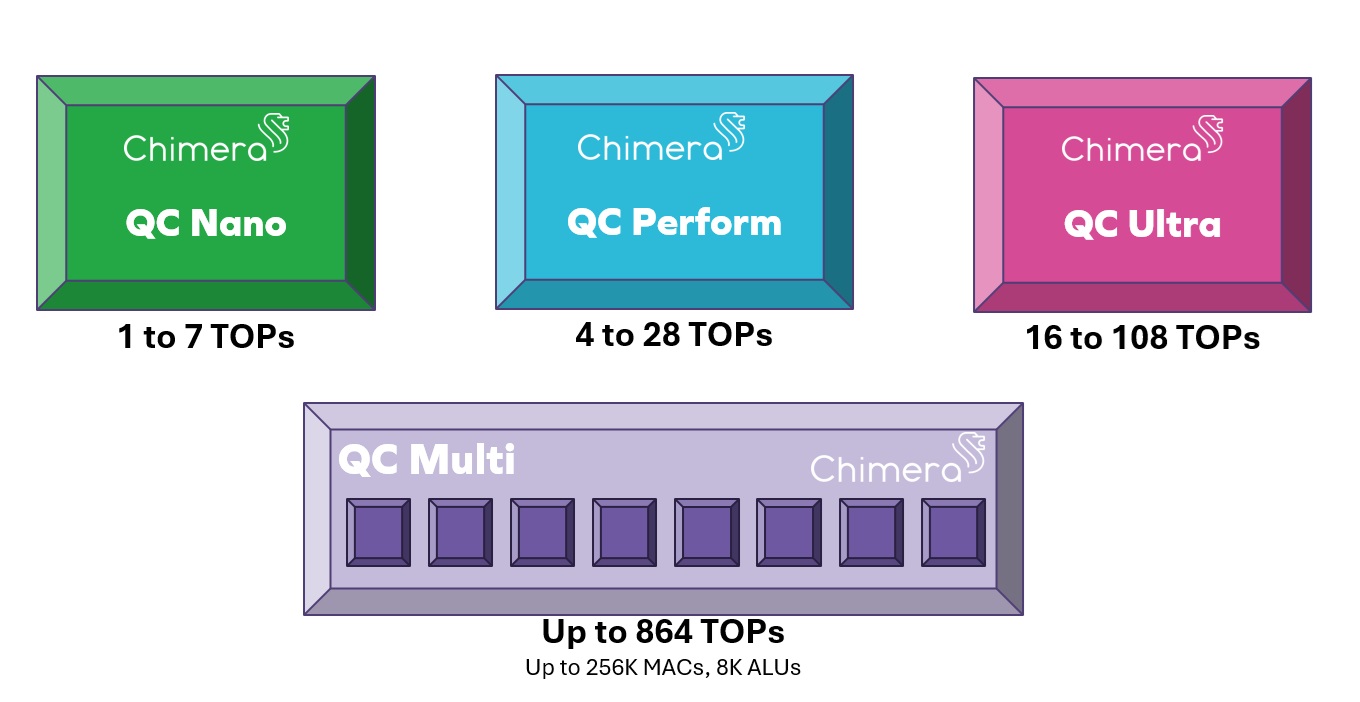
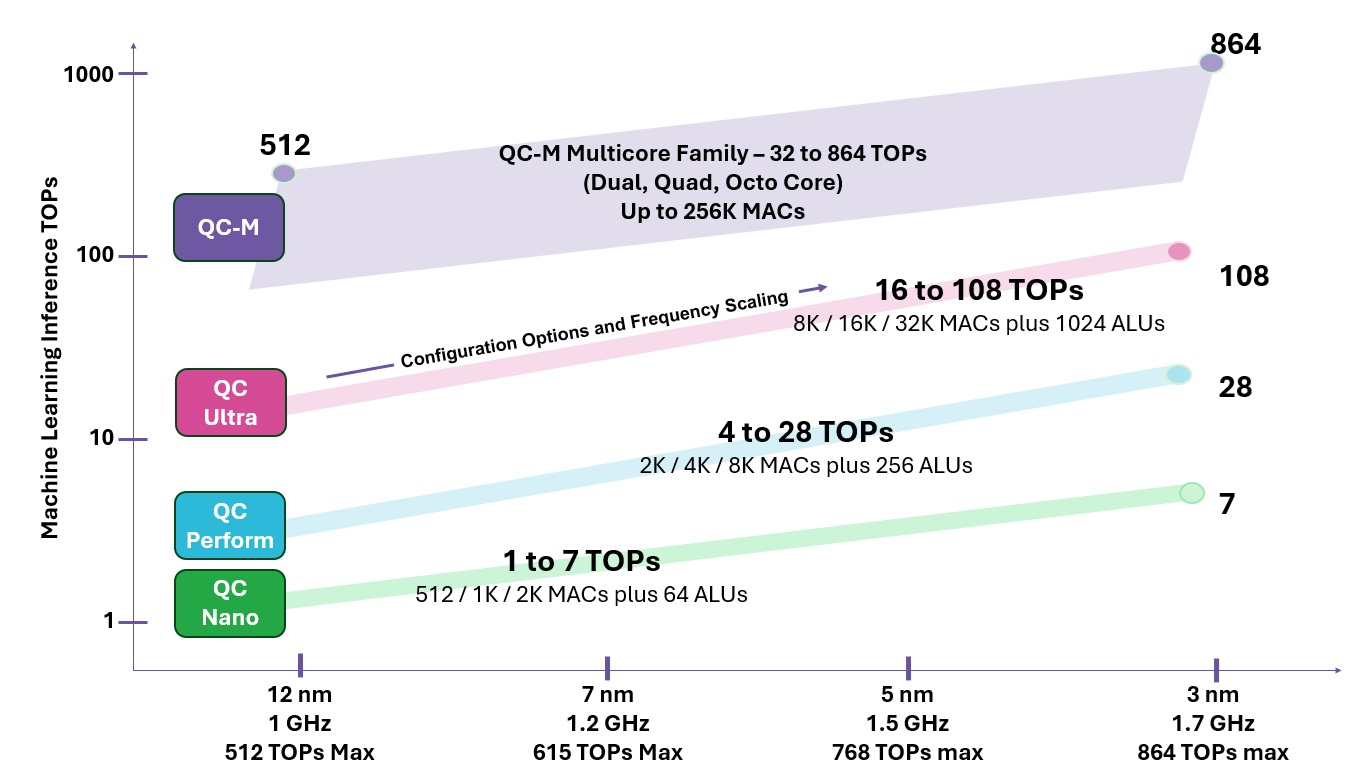
THE CHIMERA GPNPU FAMILY
The Chimera QC processor family spans a wide range of performance requirements. As a fully synthesizable processor, you can implement a GPNPU in any process technology, from older nodes to the most advanced technologies. From the single-core QC Nano all the way to 8-way QC-Multi clusters, there is a Chimera processor that meets your performance goals. Talk to us about which processor you need for your design!
KEY ARCHITECTURAL FEATURES OF A CHIMERA GPNPU
• Hybrid Von Neuman + 2D SIMD matrix architecture • 64b Instruction word, single instruction issue per clock • 7-stage, in-order pipeline • Scalar / vector / matrix instructions modelessly intermixed with granular predication • Deterministic, non-speculative execution delivers predictable performance levels • AXI Interfaces to system memory (independent data and instruction access) • Configurable Instruction cache (128/256K) • Distributed tightly coupled local register memories (LRM) with data broadcast networks within matrix array allows overlapped compute and data movement to maximize performance • Local L2 data memory (multi-bank, configurable 1MB to 16MB) minimizes off-chip DDR access, lowering power dissipation • Optimized for INT8 machine learning inference (with optional FP16 floating point MAC support) plus 32b ALU DSP ops for full C++ compiler support • Compiler-driven, fine-grained clock gating delivers power savings
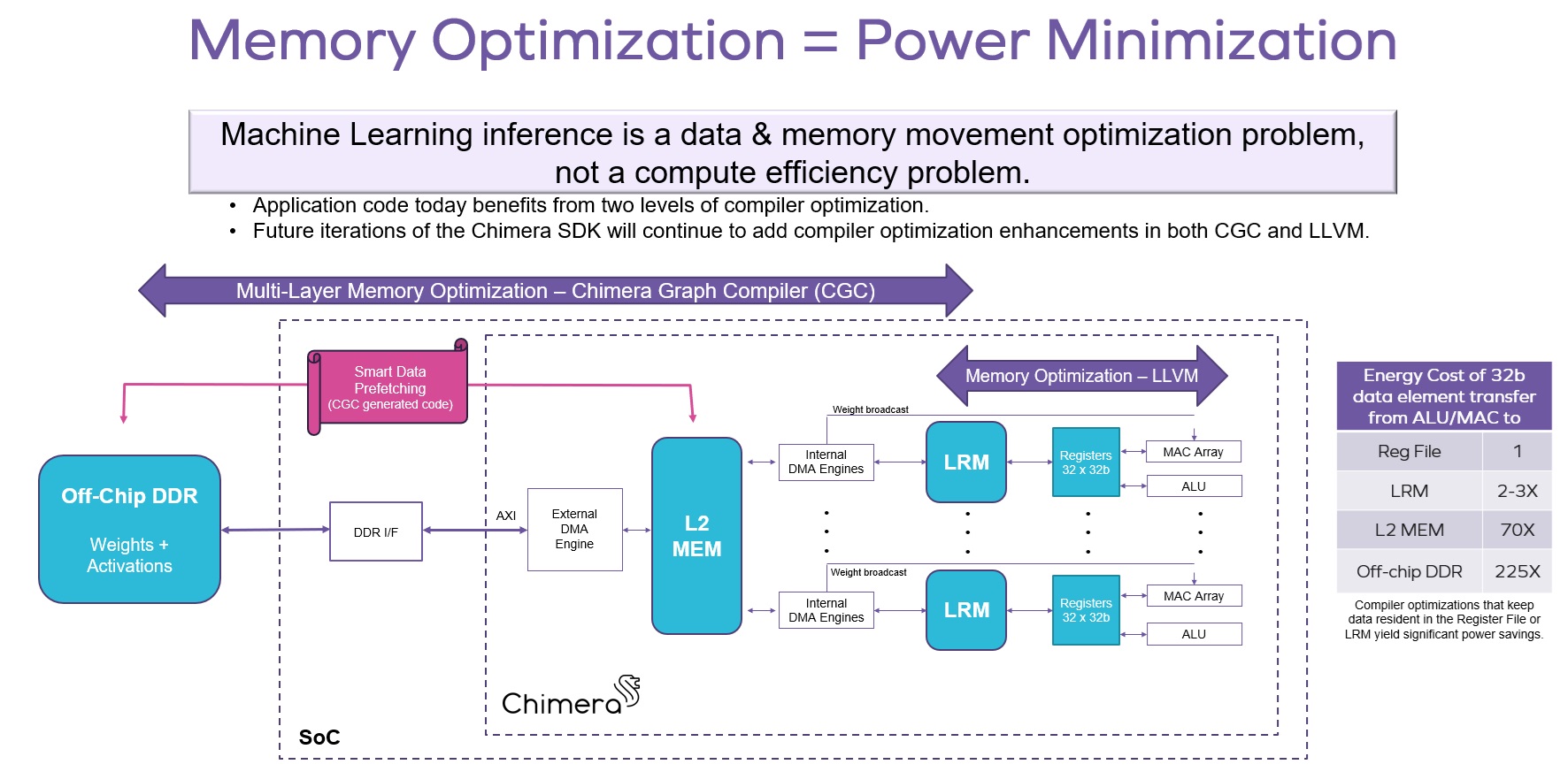
MEMORY OPTIMIZATION = POWER MINIMIZATION
Tremendous power saving are a direct result of consolidating all of the processing of the NPU, the DSP, and the realtime CPU into one GPNPU.
Machine learning inference solutions are most often performance- and power-dissipation-limited by memory system bandwidth utilization. With most state-of-the-art ML models having millions or billions of parameters, fitting an entire ML model into on-chip memory within an advanced System-on-a-Chip (SoC) is generally not possible. Therefore, smart management of available on-chip data storage of both weights and activations is a prerequisite to achieving high efficiency. To further complicate the design of SoCs the rate of change of ML models – both operator types and model topologies – far outpaces the design and deployment lifecycles of modern SoC designs. System architects must pick IP today to run models of unknown complexity in the coming years.
Many second-generation deep learning accelerators in systems today are hardwired finite state machines (FSMs) that offload several performance intensive building-block ML operators such as convolution and pooling. These FSM solutions deliver high efficiency only if the ultimate network to be run on the SoC does not waver from the limited scope of the operator parameters that have been hard-coded into the silicon. This hard-coded behavior extends to the supported memory management strategies deployed for those FSM accelerators. An FSM solution does not allow for future fine-tuning of memory management strategies as network workloads evolve. The Chimera GPNPU family solves this limitation by being fully programmable and with compiler driven DMA management.
A SoC design with a Chimera GPNPU has four levels of data storage. Off-chip DDR offers a vast lake of storage for even the largest of ML models. But accessing DDR is expensive both in terms of power dissipation and cycle count. Therefore, the Chimera GPNPU contains a configurable private buffer SRAM on chip - the L2 memory – which is managed by compiler-driven code. L2 size is determined by the SoC architect at chip design time and can range from 1 MB to 16 MB. L2MEM holds data that is temporally beneficial in speeding up algorithm execution, such as model weights and activations for deep neural networks and a variety of data and coefficients for DSP algorithms. The partitioning of the usage of L2 is software and compiler driven, offering long-term flexibility to adapt to changing ML inference workloads.
RICH DSP AND MATRIX INSTRUCTION SET
The Chimera instruction set implements a rich set of operations covering the breadth of control, DSP and tensor graph processing. The base Chimera processing element (PE) is optimized for 8-bit integer deep learning operations with a configurable hardware option to also include 16bit Floating Point (FP16) MAC hardware. In addition to the ML-focused multiply-accumulate hardware, a full set of math functions is available in each ALU to support all forms of complex DSP operations:
• 32-bit Integer MUL / ADD / SUB / Compare • 32-bit Integer DIV (iterative execution) • 32-bit Cordic function unit (Sine, Cosine, Rect. to Polar / Polar to Rect., ArcX functions) • Logarithmic and Exp functions
A set of math function libraries harnessing these special function instructions accompanies the Chimera SDK, covering an array of common signal processing routines including cordic, linear algebra, filtering and image processing functions.
330 Primrose Rd, Suite 306 Burlingame, CA 94010 USA