The Quadric Chimera Software Development Toolkit (SDK) is a comprehensive environment for the development of complex application code targeting the Chimera GPNPU. The Quadric SDK enables the mixing and matching of any data parallel algorithm whether it is expressed as machine learning graph or as traditional C++ code.
Run in Your Cloud or on premise
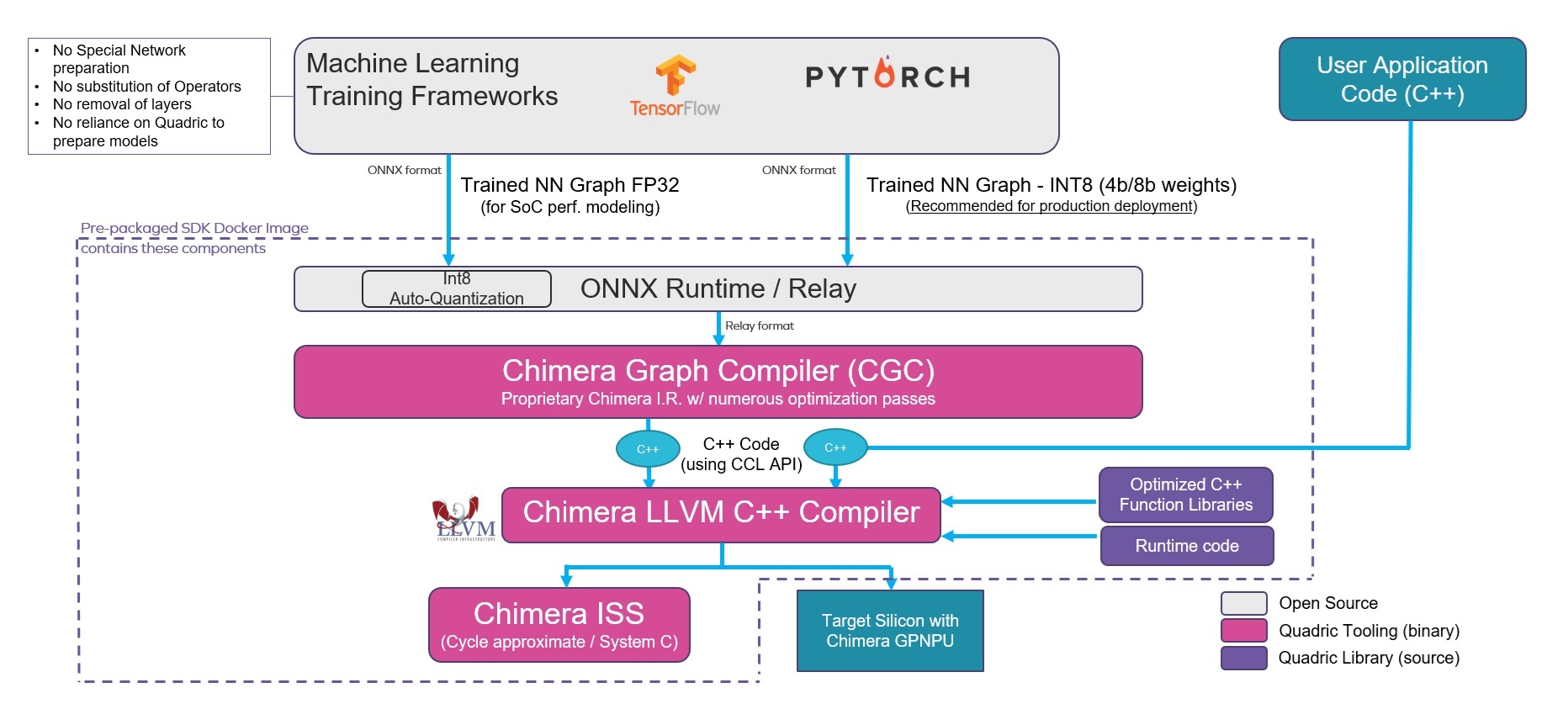
Quadric users can download a complete Docker image of the Chimera SDK for deployment on private clouds or on-premise systems. Once installed on your compute resources, you can use CGC to convert AI graphs into C++, compile your own proprietary C++ code, and profile your complete workload on the cycle approximate ISS model of the Chimera GPNPU.
The Quadric Chimera Graph Compiler (CGC) is a powerful conversion and code optimization tool that inputs an AI inference model created in the leading training frameworks, performs numerous optimizations, and outputs an optimized C++ code representation of the AI graph utilizing the Chimera Compute Library (CCL) for later compilation by the Chimera LLVM C++ compiler.
Graph Import CGC accepts input graphs in ONNX format for networks developed in PyTorch, TensorFlow or other frameworks. A number of optimizations are performed as part of the graph import phase: • Graph simplification / canonicalization • Constant propagation - removing operators with purely constant arguments, if possible • Operator legalization / conversion – converting to GPNPU-specific forms of AI/ML operators The shape and structure of the network graph is optimized to simplify operators where possible. Compatibility checks are performed to determine if all operators are supported. When an unsupported or custom operator is present in the source graph, the user has the option to partition the graph around the custom operator, write a C++ kernel for the unsupported operator, and reintegrate the new custom operator C++ kernel with CCL code generated by CGC.
Graph and Memory Optimization CGC creates a full intermediate representation of the AI/ML graph and performs multiple passes of optimization with the twin aims of optimizing performance and memory bandwidth utilization.
Memory optimization techniques include: • Tensor format layout analysis (both L2 and LRM) • Fusion in Local Memory (FILM) - merging of operations to preserve data within LRM and avoid costly intermediate activation writeback. • Array-level memory adapters & tensor shape transformations • Bank conflict minimization, defragmentation • Predictive weight prefetching
Chimera LLVM C++ Compiler & Instruction Set Simulator
The Chimera LLVM C++ compiler utilizes the industry state of the art LLVM compiler infrastructure with a Quadric-specific code generation back end that emits assembly code specific to the Chimera instruction set.
The Chimera Instruction Set Simulator (ISS) is an executable model of the Chimera GPNPU core that is bundled with the Chimera SDK. The ISS can be utilized both in a standalone mode to profile and tune application code in isolation, or as a callable System C transaction-level model bundled into a more comprehensive virtual prototype of an SoC where more accurate memory model behavior can be used to fine-tune your Chimera code more precisely.
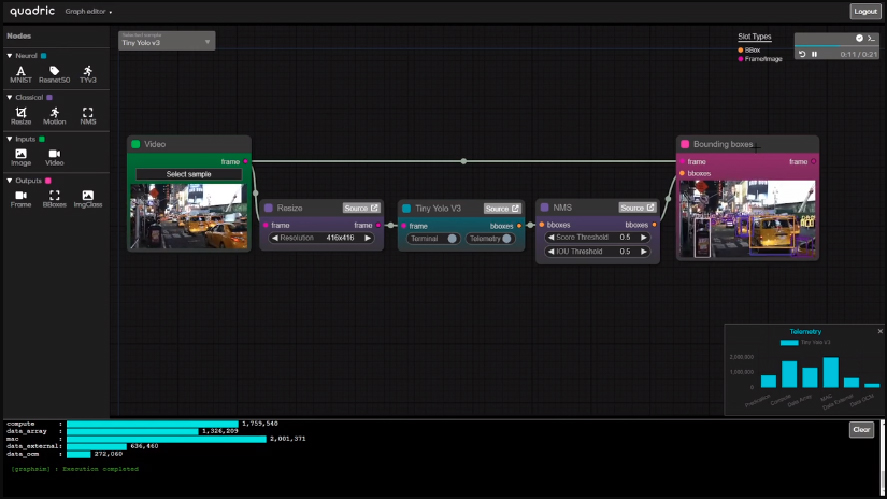
The Chimera ISS provides extensive profiling of cycle counts, data bandwidth usage, and power profiles of each unique ML workload.
 Try DevStudio
Try DevStudio