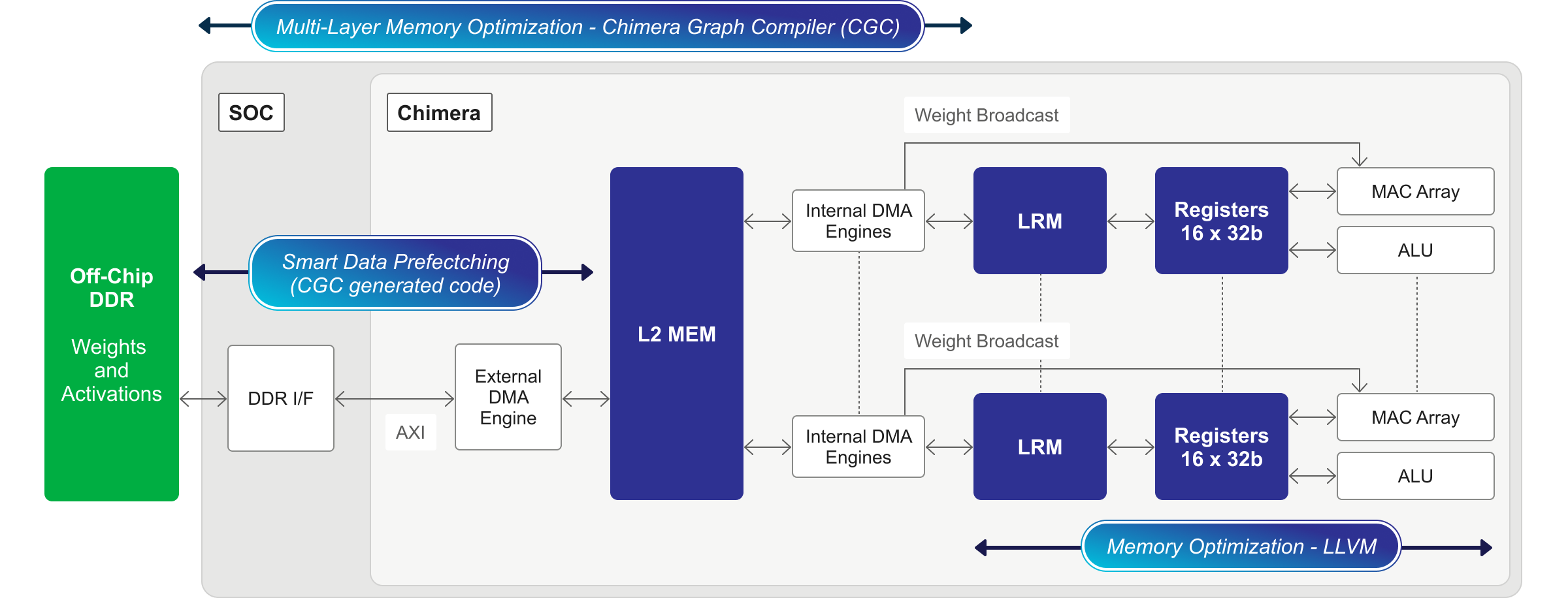

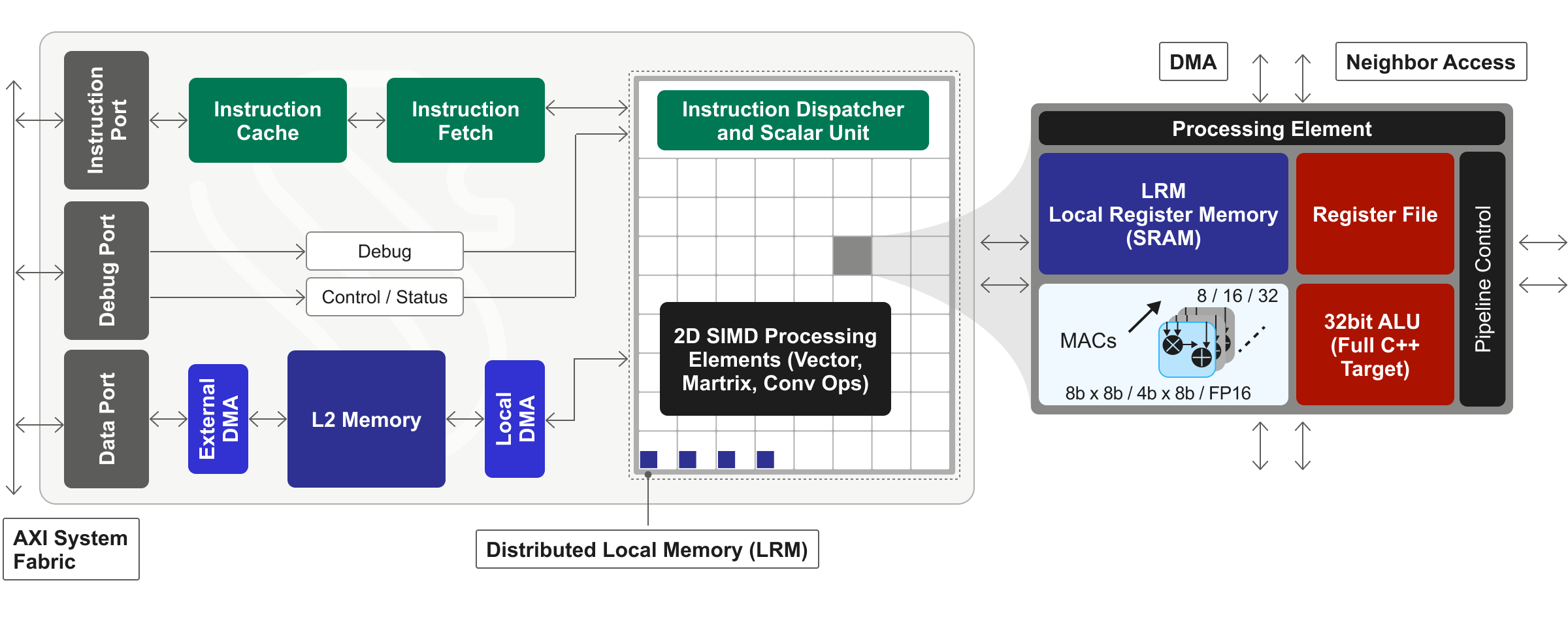
Modern System-on-Chip (SoC) architectures deploy complex algorithms that mix traditional C++ based code with newly emerging and fast-changing machine learning (ML) - or "AI" - inference code. This combination of graph code commingled with C++ code is found in numerous chip subsystems, most prominently in vision and imaging subsystems, radar and lidar processing, communications baseband subsystems, and a variety of other data-rich processing pipelines. Only Quadric’s Chimera GPNPU architecture can deliver high AI/ML inference performance and run complex, data-parallel C++ code on the same fully programmable processor.
Compared to other inference architectures that force the software developer to artificially partition an algorithm solution between two or three different kinds of processors, Quadric’s Chimera processors deliver a massive uplift in software developer productivity while also providing current-day graph processing efficiency coupled with long-term future-proof flexibility.
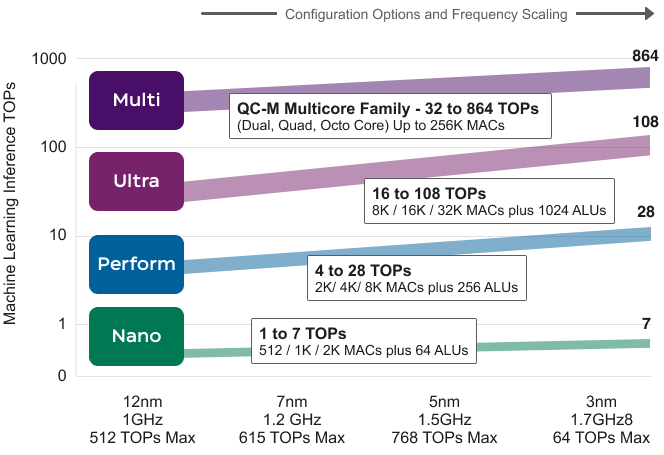
Quadric’s Chimera GPNPUs are licensable processor IP cores delivered in synthesizable source RTL form. Blending the best attributes of both neural processing units (NPUs) and digital signal processors (DSPs), Chimera GPNPUs are aimed at inference applications in a variety of high-volume end applications including mobile devices, digital home applications, automotive and network edge compute systems.