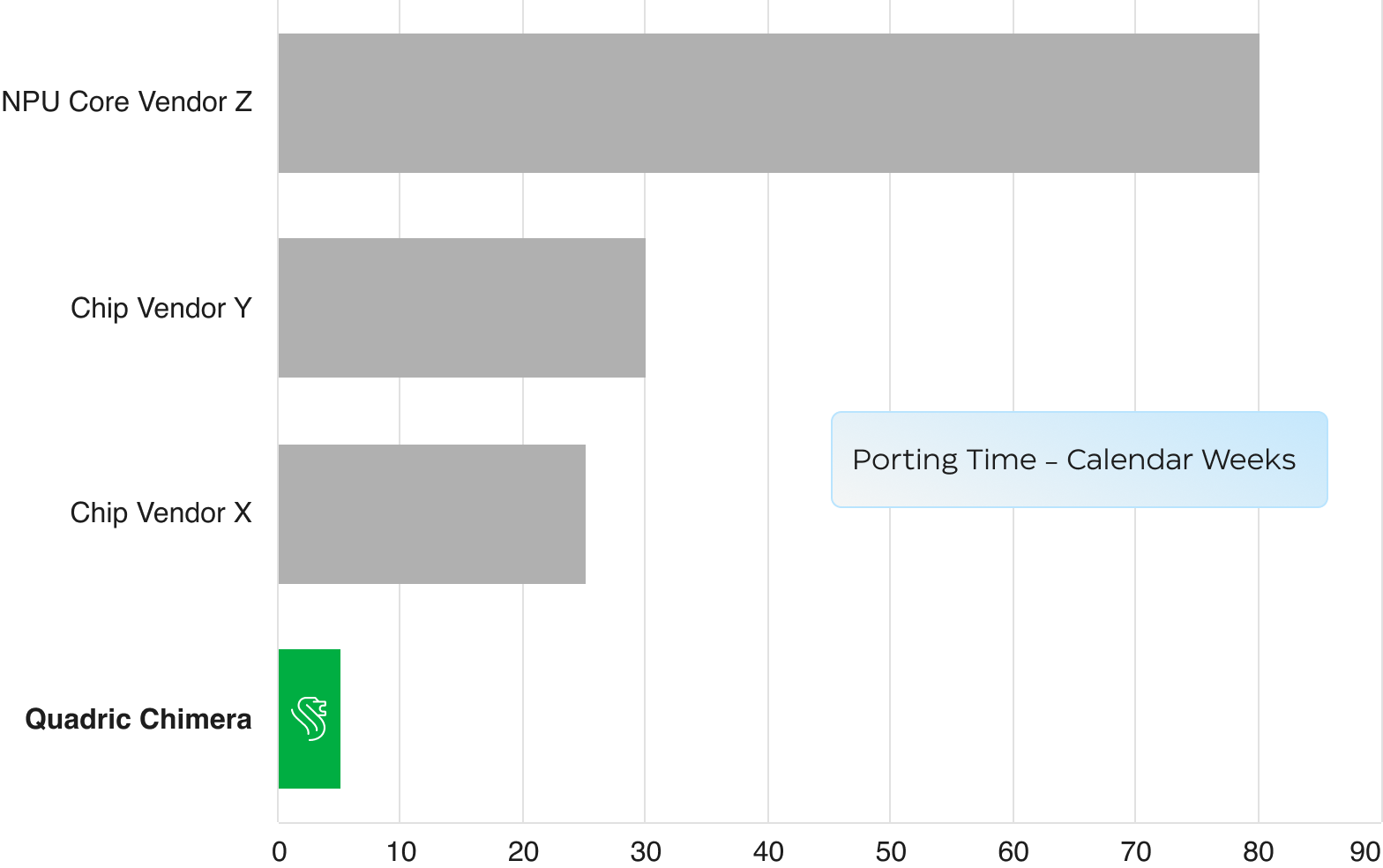
In July of 2023, Meta announced the Llama2 large language model (LLM) designed to be run on-device, not in the cloud. This exciting breakthrough model prompted numerous SoC vendors and IP core vendors to announce intent to support Llama2 - far into the future. Early announcements promised Llama2 support in 2024, or a new IP core available for early 2024 tape-out and thus 2025 shipment.
Chimera is a fully programmable NPU - programmable in C++. A small team of Quadric engineers ported and optimized Llama2 in just under 5 weeks! If YOUR chip had a Chimera GPNPU you could have raced to the market a half-year faster than your competition!
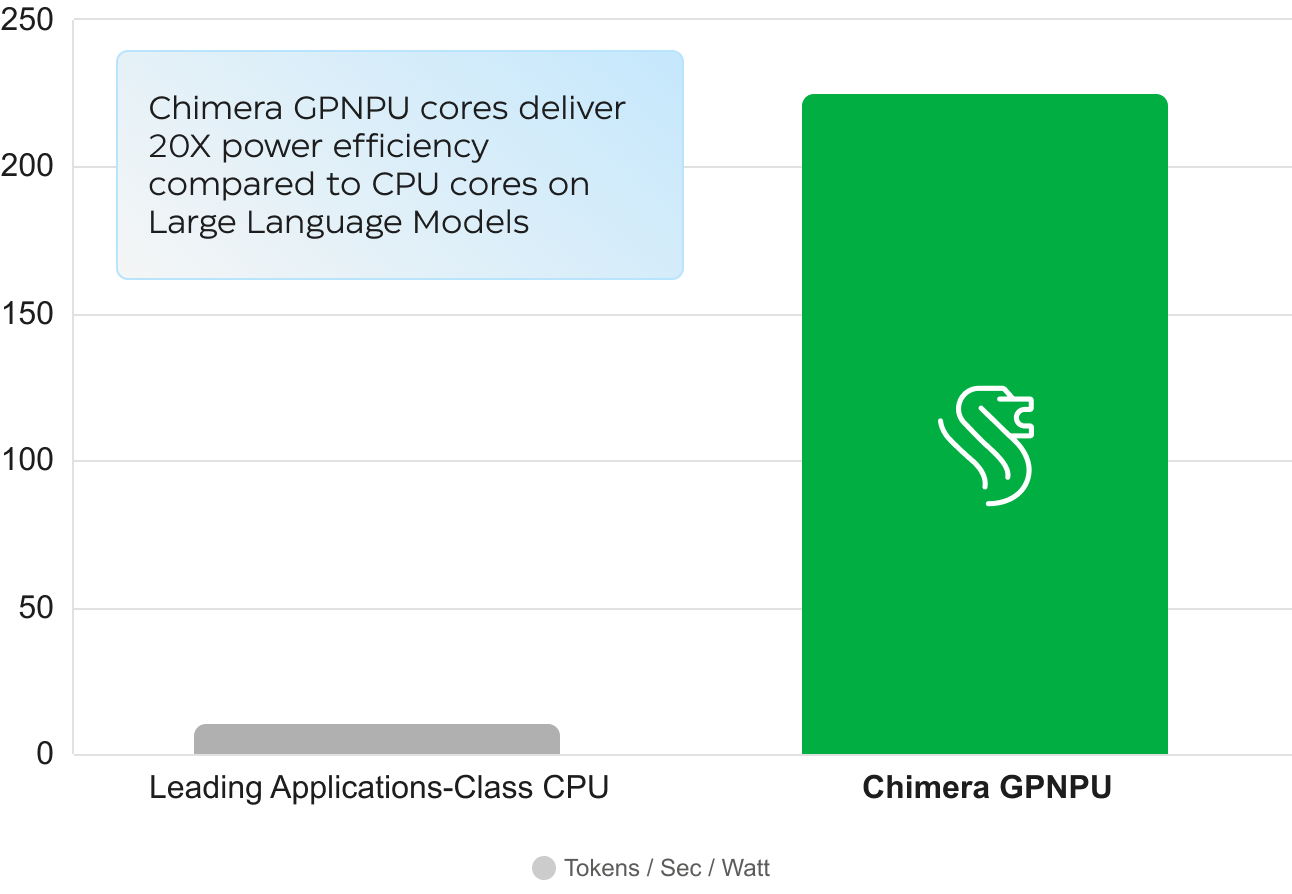
Porting a new AI/ML workload to Chimera cores is fast - because its done by compiling an ONNX graph into C++ using our state of the art Chimera Graph Compiler (CGC). In the two years since the Llama2 model introduction, our CGC compiler has matured to now automatically handle many forms of the self-attention layers in the hundreds of new LLMs invented since 2023. That means today's newest LLMs can "lower" (be converted from ONNX to C++) in even less time - with some models compiling in just minutes. Yet Chimera processors also deliver Inference efficiency dramatically higher than what CPUs or GPUs provide. Chimera GPNPUs uniquely combine the easy programmability of a processor with the efficiency of a NPU "accelerator".
Experience Chimera yourself
Sign-in to your existing account, or sign-up for a new Quadric DevStudio account today and see it for yourself.