The biggest mistake a chip design team can make in evaluating AI acceleration options for a new SoC is to rely entirely upon spreadsheets of performance numbers from the NPU vendor without going through the exercise of porting one or more new machine learning networks themselves using the vendor toolsets.
Why is this a huge red flag? Most NPU vendors tell prospective customers that (1) the vendor has already optimized most of the common reference benchmarks, and (2) the vendor stands ready and willing to port and optimize new networks in the future. It is an alluring idea – but it’s a trap that won’t spring until years later. Unless you know today that the Average User can port his/her own network, you might be trapped in years to come!
Rely on NPU Vendor at Your Customers’ Customers Expense!
To the chip integrator team that doesn’t have a data science cohort on staff, the daunting thought of porting and tuning a complex AI graph for a novel NPU accelerator is off-putting. The idea of doing it for two or three leading vendors during an evaluation is simply a non-starter! Implicit in that idea is the assumption that the toolsets from NPU vendors are arcane, and that the multicore architectures they are selling are difficult to program. It happens to be true for most “accelerators” where the full algorithm must be ripped apart and mapped to a cluster of scalar compute, vector compute and matrix compute engines. Truly it is better to leave that type of brain surgery to the trained doctors!
But what happens after you’ve selected an AI acceleration solution? After your team builds a complex SoC containing that IP core? After that SoC wins design sockets in the systems of OEMs? What happens when those systems are put to the test by buyers or users of the boxes containing your leading-edge SoC?
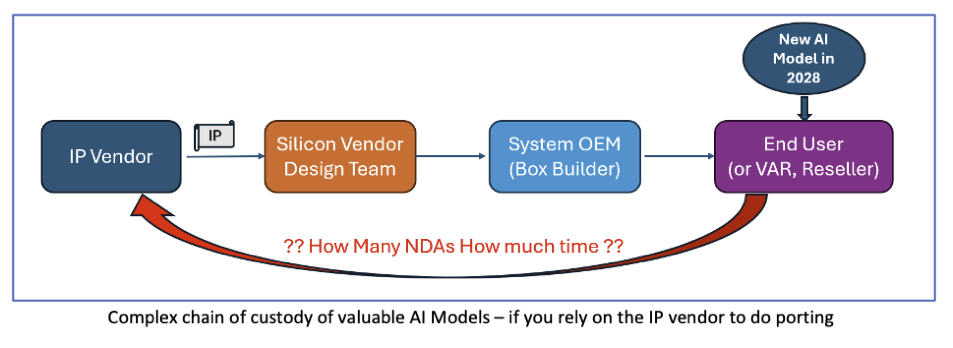
Who Ports and Optimizes the New AI Network in 2028?
The AI acceleration IP selection decision made today – in 2024 – will result in end users in 2028 or 2030 needing to port the latest and greatest breakthrough machine learning models to that vintage 2024 IP block. Relying solely on the IP vendor to do that porting adds unacceptable business risks!
Layers Of Risk
Business Relationship Risk: Will the End User – likely with a proprietary trained model – feel comfortable relying on a chip vendor or an IP vendor they’ve never met to port and optimize their critical AI model? What about the training dataset? If model porting requires substituting operators to fit the limited set of hardwired operators in the NPU accelerator, the network will need to be retrained and requantized – which means getting the training set into the hands of the IP vendor?
Legal Process Risk: How many NDAs will be needed – with layer upon layer of lawyer time and data security procedures – to get the new model into the hands of the IP vendor for creation of new operators or tuning of performance?
Porting Capacity Risk: Will the IP vendor have the capacity to port and optimize all the models needed? Or will the size of the service team inside the IP vendor become the limiting factor in the growth of the business of the system OEM, and hence the sales of the chips bearing the IP?
Financial Risk: IP vendor porting capacity can never be infinite no matter how eager they are to take on that kind of work – how will they prioritize porting requests? Will the IP vendor auction off porting priority to the “highest bidder”? In a game of ranking customers by importance or willingness to write service fee checks, someone gets shoved the end of the list and goes home crying.
Survivor Risk: The NPU IP segment is undergoing a shakeout. The herd of more than twenty would-be IP vendors will be thinned out considerably in four years. Can you count on the IP vendor of 2024 to still have a team of dedicated porting engineers in 2030?
In What Other Processor Category Does the IP Vendor Write All the End User Code?
Here’s another way to look at the situation: can you name any other category of processor – CPU, DSP, GPU – where the chip design team expects the IP vendor to “write all the software” on behalf of the eventual end user? Of course not! A CPU vendor delivers world-class compilers along with the CPU core, and years later the mobile phone OS or the viral mobile App software products are written by the downstream users and integrators. Neither the core developer nor the chip developer get involved in writing a new mobile phone app! The same needs to be true for AI processors – toolchains are needed that empower the average user – not just the super-user core developer - to easily write or port new models to the AI platform.
A Better Way – Leading Tools that Empower End Users to Port & Optimize
Quadric’s fully programmable GPNPU – general purpose NPU – is a C++ programmable processor combining the power-performance characteristics of a systolic array “accelerator” with the flexibility of a C++ programmable DSP. The toolchain for Quadric’s Chimera GPNPU combines a Graph Compiler with an LLVM C++ compiler – a toolchain that Quadric delivers to the chip design team and that can be passed all the way down the supply chain to the end user. End users six years from now will be able to compile brand new AI algorithms from the native Pytorch graph into C++ and then into a binary running on the Chimera processor. End users do not need to rely on Quadric to be their data science team or their model porting team. But they do rely on the world-class compiler toolchain from Quadric to empower them to rapidly port their own applications to the Chimera GPNPU core.
© Copyright 2024 Quadric All Rights Reserved Privacy Policy