A common approach in the industry to building an on-device machine learning inference accelerator has relied on the simple idea of building an array of high-performance multiply-accumulate circuits – a MAC accelerator. This accelerator was paired with a highly programmable core to run other, less commonly used layers in machine learning graphs. Dozens of lookalike architectures have been built over the past half-decade with this same accelerator plus fallback core concept to solve the ML inference compute problem.
Yet, those attempts haven’t solved the ML inference compute problem. There’s one basic reason. This partitioned, fallback-style architecture simply doesn’t work for modern networks. It worked quite well in 2021 to run classic CNNs from the Resnet era (circa 2015-2017). But now it’s failing to keep up with modern inference workloads.
CNNs and all new transformers are comprised of much more varied ML network operators and far more complex, non-MAC functions than the simple eight (8) operator Resnet-50 backbone of long ago.
For five years, Quadric has been saying that the key to future-proofing your ML solution is to make it programmable in a much more efficient way than just tacking on a programmable core to a bunch of Macs.
There were times when it felt quite lonely being the only company telling the world “Hey, you’re not looking at the new wave of networks. MACs are not enough! It’s the fully functional ALUs that matter!” So imagine our joy at finding one of market titans – Qualcomm – belatedly coming around to our way of thinking!
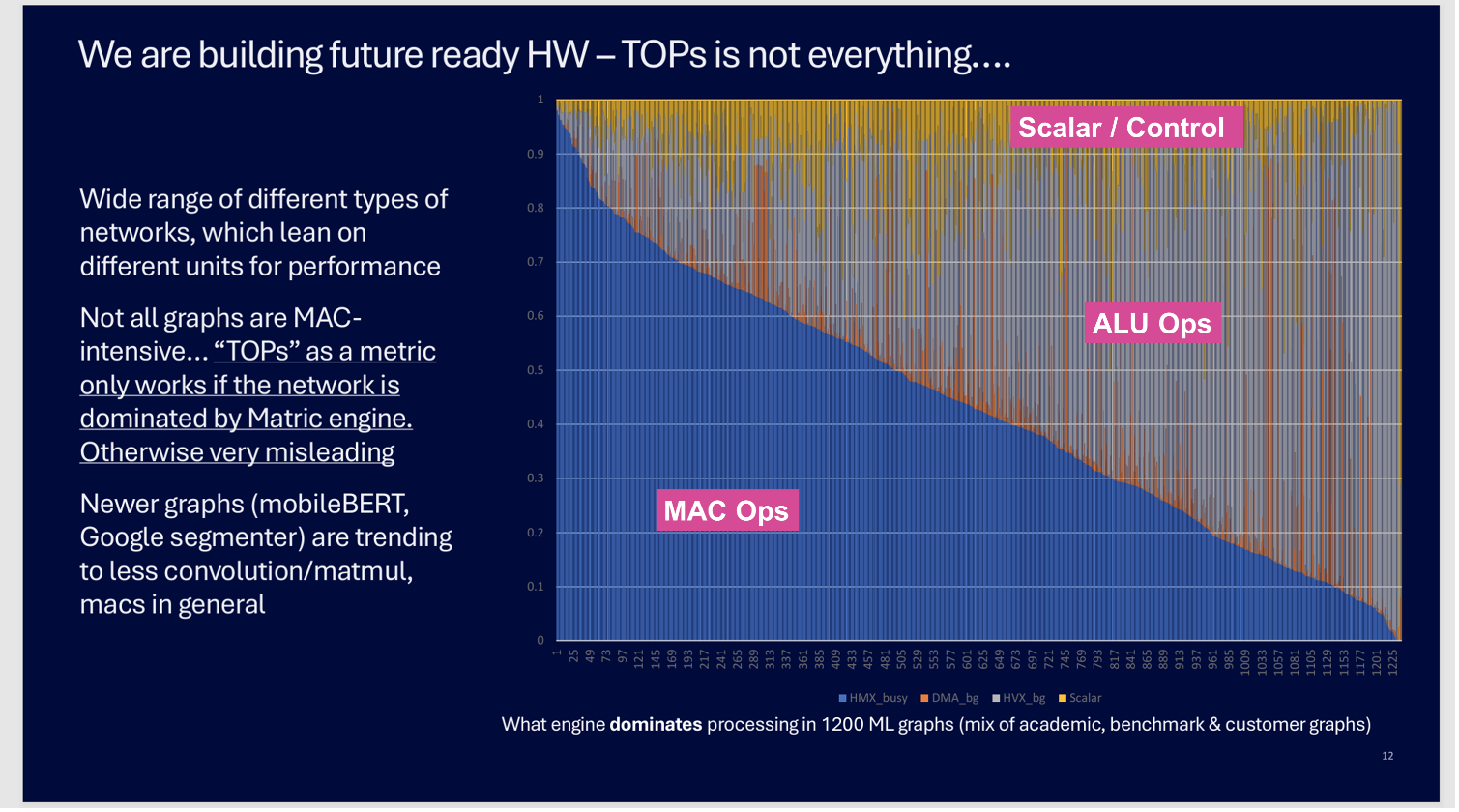
In November last year at the Automotive Compute Conference in Munich, a Qualcomm keynote speaker featured this chart in his presentation.
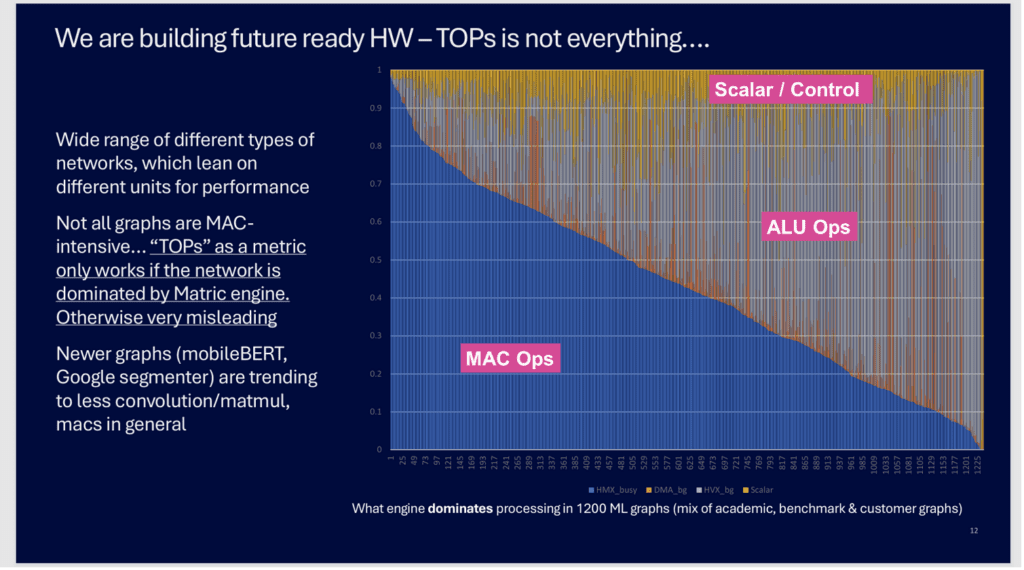
Qualcomm’s Analysis Proves it’s Much More Than MACs
The chart above shows Qualcomm’s analysis of over 1200 different AI/ML networks that they have profiled for their automotive chipsets. The Y axis shows the breakdown of the performance demands for each network, color-coded by how much of the compute is multiply-accumulate (MAC) functions – Blue; other vector DSP type calculations – ALU Operations (Grey, Orange); and pure scalar/control code - Yellow. The 3-segment breakdown by Qualcomm corresponds to how Qualcomm’s Hexagon AI accelerator is designed – with three unique computing blocks.
The first 50+ networks on the lefthand side are indeed MAC dominated, requiring MAC accelerated hardware for >90% of the time. But less than half of the total networks are more than 50% MAC dominated. And some of these newer networks have little or no classical MAC layers at all!
Can You Afford to Use 64 DSPs?
At first blush, the argument made by Qualcomm seems plausible: there is a MAC engine for matrix-dominated networks, and a classic DSP core for networks that are mostly ALU operation bound. Except they leave out two critical pieces of information:
Today’s largest licensable DSPs have 512-bit wide vector datapaths. That translates into 16 parallel ALU operations occurring simultaneously. But common everyday devices – AI PCs and mobile phones – routinely feature 40 TOPs matrix accelerators. That 40 TOP accelerator can produce 2000+ results of 3x3 convolutions each clock cycle. 2000 versus 16. That is a greater than two order of magnitude mismatch. Models run on the DSP are thus two order of magnitude slower than similar models run on the accelerator? Models that need to ping-pong between the different types of compute get bottlenecked on the slow DSP?
Chimera GPNPU – A Better Way!
If silicon area and cost are not a concern, we suppose you could put a constellation of 64 DSPs on chip to make non-MAC networks run as fast as the MAC dominated networks. 64 discrete DSPs with 64 instruction caches, 64 data caches, 64 AXI interfaces, etc. Good luck programming that!
Or, you could use one revolutionary Chimera GPNPU processor that integrates a full-function 32-bit ALU with each cluster of 16 or 32 MACs. Up to 1024 ALUs in a single core, with only one instruction fetch and one AXI data port. Chimera GPNPUs have matched and balanced compute throughput for both MAC and ALU compute so no matter what type of network you choose to run, they all run fast and highly parallel.
No Gimmicks, Just Data
If you want unfiltered, full disclosure of performance data for a leading machine learning processing solution, head over to Quadric’s online DevStudio tool. In DevStudio you will find more than 120 AI benchmark models, each with links to the source model, all the intermediary compilation results and reports ready for your inspection, and data from hundreds of cycle-accurate simulation runs on each benchmark model so you can compare all the possible permutations of on-chip memory size options, assumptions about off-chip DDR bandwidth, and presented with a fully transparent Batch=1 set of test conditions. And you can easily download the full SDK to run your own simulation of a complete signal chain, or a batched simulation to match your system needs.