On Chimera QC Ultra it runs 28x faster than DSP+NPU
ConvNext is one of today’s leading new ML networks. Frankly, it just doesn’t run on most NPUs. So if your AI/ML solution relies on an NPU plus DSP for fallback, you can bet ConvNext needs to run on that DSP as a fallback operation. Our tests of expected performance on a DSP + NPU is dismal – less than one inference per second trying to run the ConvNext backbone if the novel Operators – GeLu and LayerNorm – are not present in the hardwired NPU accelerator and instead those Ops ran on the largest and most powerful DSP core on the market today.
This poor performance makes most of today’s DSP + NPU silicon solutions obsolete. Because that NPU is hardwired, not programmable, new networks cannot efficiently be run.
So what happens when you run ConvNext on Quadric’s Chimera QC Ultra GPNPU, a fully programmable NPU that eliminates the need for a DSP for fallback? The comparison to the DSP-NPU Fallback performance is shocking: Quadric’s Chimera QC Ultra GPNPU is 28 times faster (28,000%!) than the DSP+NPU combo for the same large input image size: 1600 x 928. This is not a toy network, but a real useful image size. And Quadric has posted results for not just one but three different variants of the ConvNext: both Tiny and Small variants, and with input image sizes at 640x640, 800x800, 928x1600. The results are all available for inspection online inside the Quadric Developers’ Studio.
Fully Compiled Code Worked Perfectly
Why did we deliver three different variants of ConvNext all at one time? And why were those three variants added to the online DevStudio environment at the same time as more than 50 other new network examples a mere 3 months (July 2024) after our previous release (April)? Is it because Quadric has an army of super-productive data scientists and low-level software coders who sat chained to their computers 24 hours a day, 7 days a week? Or did the sudden burst of hundreds of new networks happen because of major new feature improvements in our market-leading Chimera Graph Compiler (CGC)? Turns out that it is far more productive – and ethical - for us to build world-class graph compilation technology rather than violate labor laws.
Our latest version of the CGC compiler fully handles all the graph operators found in ConvNext, meaning that we are able to take model sources directly from the model repo on the web and automatically compile the source model to target our Chimera GPNPU. In the case of ConvNext, that was a repo on Github from OpenMMLab with a source Pytorch model. Login to DevStudio to see the links and sources yourself! Not hand-crafted. No operator swapping. No time-consuming surgical alteration of the models. Just a world-class compilation stack targeting a fully-programmable GPNPU that can run any machine learning model.
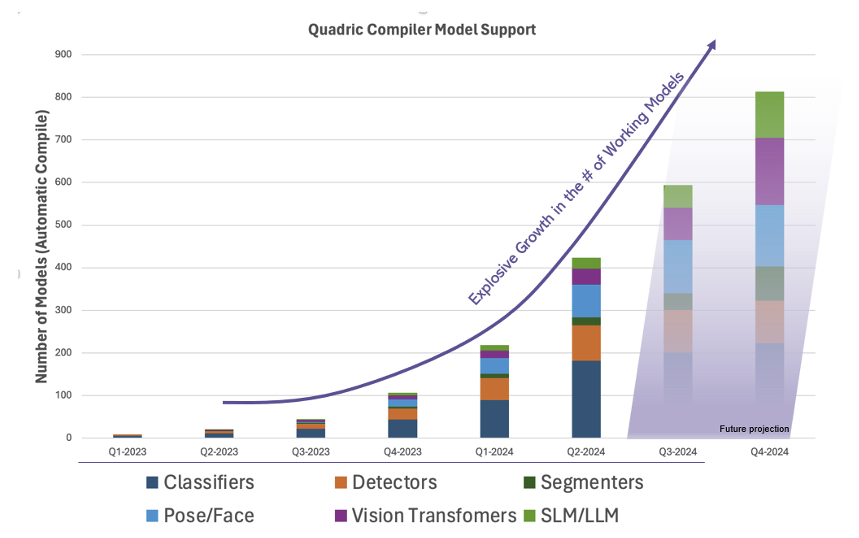
Lots of Working Models
Perhaps more impressive than our ability to support ConvNext – at a high 28 FPS frame rate – is the startling increase in the sheer number of working models that compile and run on the Chimera processor as our toolchain rapidly matures (see chart).
Faster Code, Too
Not only did we take a huge leap forward in the breadth of model support in this latest software release, but we also continue to deliver incremental performance improvements on previous running models as the optimization passes inside the CGC compiler continue to expand and improve. Some networks saw improvements of over 50% in just the past 3 months. We know our ConvNext numbers will rapidly improve.
The performance improvements will continue to flow in the coming months and years as our compiler technology continues to evolve and mature Unlike a hardwired accelerator with fixed feature sets and fixed performance the day you tape-out, a processor can continue to improve as the optimizations and algorithms in the toolchain evolve.
Programmability Provides Futureproofing
By merging the best attributes of dataflow array accelerators with full programmability, Quadric delivers high ML performance while maintaining endless programmability. The basic Chimera architecture pairs a block of multiply-accumulate (MAC) units with a full-function 32-bit ALU and a small local memory. This MAC-ALU-memory building block – called a processing element (PE) - is then tiled into a matrix of PEs to form a family of GPNPUs offering from 1 TOP to 864 TOPs. Part systolic array and part DSP, the Chimera GPNPU delivers what others fails to deliver – the promise of efficiency and complete futureproofing.