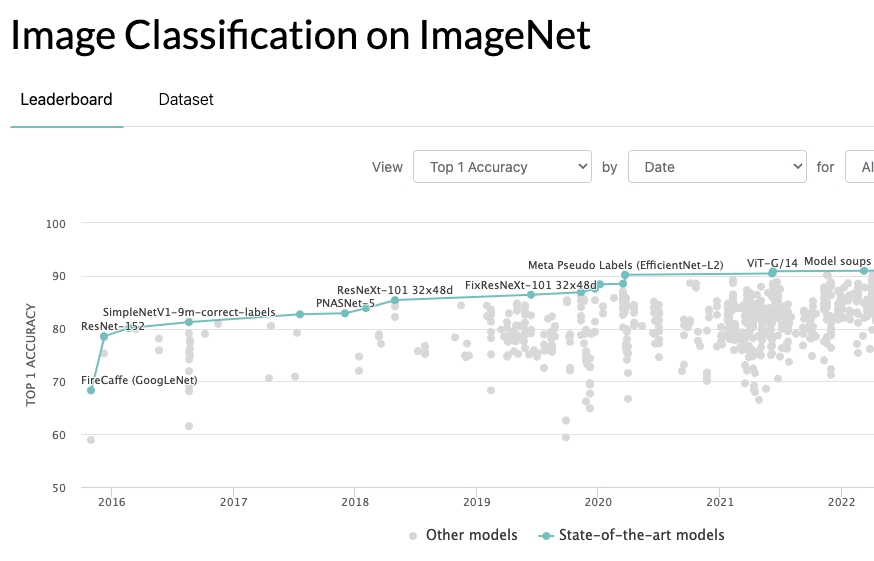
The ResNet family of machine learning algorithms, introduced to the AI world in 2015, pushed AI forward in new ways. However, today’s leading edge classifier networks – such as the Vision Transformer (ViT) family - have Top 1 accuracies a full 10% points of accuracy ahead of the top-rated ResNet in the leaderboard. ResNet is old news. Surely other new algorithms will be introduced in the coming years.
Let’s take a look back at how far we’ve come. Shortly after introduction, new variations were rapidly discovered that pushed the accuracy of ResNets close to the 80% threshold (78.57% Top 1 accuracy for ResNet-152 on ImageNet). This state-of-the-art performance at the time coupled with the rather simple operator structure that was readily amenable to hardware acceleration in SoC designs turned ResNet into the go-to litmus test of ML inference performance. Scores of design teams built ML accelerators in the 2018-2022 time period with ResNet in mind.
These accelerators – called NPUs – shared one common trait – the use of integer arithmetic instead of floating-point math. Integer formats are preferred for on-device inference because an INT8 multiply-accumulate (the basic building block of ML inference) can be 8X to 10X more energy efficient than executing the same calculation in full 32-bit floating point. The process of converting a model’s weights from floating point to integer representation is known as quantization. Unfortunately, some degree of fidelity is always lost in the quantization process.
NPU designers have, in the past half-decade, spent enormous amounts of time and energy fine-tuning their weight quantization strategies to minimize the accuracy loss of an integer version of ResNet compared to the original Float-32 source (often referred to as Top-1 Loss). For most builders and buyers of NPU accelerators, a loss of 1% or less is the litmus test of goodness. Some even continue to fixate on that number today, even in the face of dramatic evidence that suggests now-ancient networks like ResNet should be relegated to the dustbin of history. What evidence, you ask? Look at the “leaderboard” for ImageNet accuracy that can be found on the Papers With Code website:
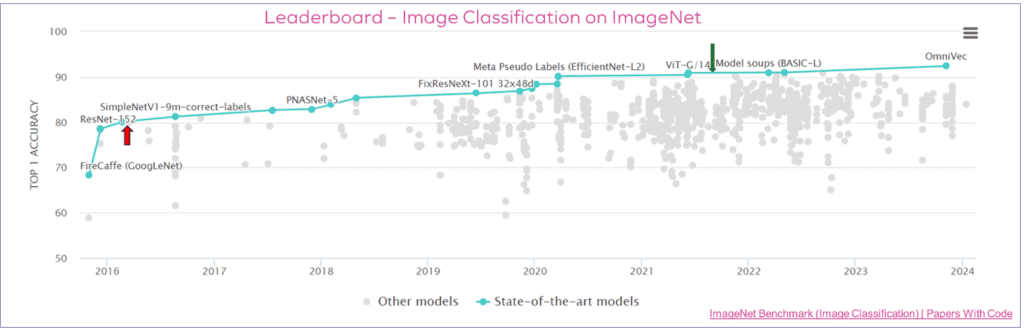
https://paperswithcode.com/sota/image-classification-on-imagenet
It’s Time to Leave the Last Decade Behind
As the leaderboard chart aptly demonstrates, today’s leading edge classifier networks – such as the Vision Transformer (ViT) family - have Top 1 accuracies exceeding 90%, a full 10% points of accuracy ahead of the top-rated ResNet in the leaderboard. For on-device ML inference performance, power consumption and inference accuracy must all be balanced for a given application. In applications where accuracy really matters – such as automotive safety applications –design teams should be rushing to embrace these new network topologies to gain the extra 10+% in accuracy.
It certainly makes more sense to embrace 90% accuracy thanks to a modern ML network – such as ViT, or SWIN transformer, or DETR - rather than fine-tuning an archaic network in pursuit of its original 79% ceiling? Of course. So then why haven’t some teams made the switch?
Why Stay with an Inflexible Accelerator?
Perhaps those who are not Embracing The New are limited because they chose accelerators with limited support of new ML operators. If a team implemented a fixed-function accelerator four years ago in an SoC that cannot add new ML operators, then many newer networks – such as Transformers – cannot run on those fixed-function chips today. A new silicon respin – which takes 24 to 36 months and millions of dollars – is needed.
But one look at the leaderboard chart tells you that picking a fixed-function set of operators now in 2024 and waiting until 2027 to get working silicon only repeats the same cycle of being trapped as new innovations push state-of-the-art accuracy, or retains accuracy with less computational complexity. If only there was a way to run both known networks efficiently and tomorrow’s SOTA networks on device with full programmability!
Use Programmable, General Purpose NPUs (GPNPU) Luckily, there is now an alternative to fixed-function accelerators. Since mid-2023 Quadric has been delivering its Chimera General-Purpose NPU (GPNPU) as licensable IP. With a TOPs range scaling from 1 TOP to 100s of TOPs, the Chimera GPNPU delivers accelerator-like efficiency while maintaining C++ programmability to run any ML operator, and we mean any. Any ML graph. Any new network. Even ones that haven’t been invented yet. Embrace the New!