In today’s disaggregated electronics supply chain the (1) application software developer, (2) the ML model developer, (3) the device maker, (4) the SoC design team and (5) the NPU IP vendor often work for as many as five different companies. It can be difficult or impossible for the SoC team to know or predict actual AI/ML workloads and full system behaviors as many as two or three years in advance of the actual deployment. But then how can that SoC team make good choices provisioning compute engines and adequate memory resources for the unknown future without defaulting to “Max TOPS / Min Area”?
There has to be a smarter way to eliminate bottlenecks while determining the optimum local memory for AI/ML subsystems.
Killer Assumptions
“I want to maximize the MAC count in my AI/ML accelerator block because the TOPs rating is what sells, but I need to cut back on memory to save cost,” said no successful chip designer, ever.
Emphasis on “successful” in the above quote. We’ve heard comments like this many times. Chip architects – or their marketing teams – try to squeeze as much brag-worthy horsepower into a new chip design as they can while holding down silicon cost.
Many SoC teams deploy home-grown accelerators for machine learning inference. Those internal solutions often lack accurate simulation models that can be plugged into larger SoC system simulations, and they need to be simulated at the logic level in Verilog to determine memory access patterns to the rest of the system resources. With slow gate-level simulation speeds, often the available data set gathered is small and limited to one or two workloads profiled. This lack of detailed information can entice designers into several deadly assumptions.
Killer assumption number one is that the memory usage patterns of today’s reference networks – many of which are already five or more years old (think ResNet) - will remain largely unchanged as networks evolve.
The second risky assumption is to simplistically assume a fixed percentage of available system external bandwidth that doesn’t account for resource contention over time.
Falling prey to those two common traps can lead the team to declare design goals have been met with just a small local memory buffer dedicated to the NPU accelerator. Unfortunately, they find out after silicon is in-hand that perhaps newer models have different data access patterns that require smaller, more frequent random accesses to off-chip memory – a real performance killer in systems that perform best with large burst transfers.
If accelerator performance depends on the next activation data element or network weight being ready for computation by your MAC array within a few clock cycles, waiting 1000 cycles to gain access to the DDR channel only to underutilize it with a tiny data transfer can wreak havoc with achievable performance.
Using Big Memory Buffers Might Not Solve the Problem
You might think the obvious remedy to the conundrum is to provision more SRAM on chip as buffer memory than the bare minimum required. That might help in some circumstances. Or it might just add cost but not solve the problem if a hardwired state machine accelerator with inflexible memory access and stride patterns continues to request an excessive number of tiny block transfer requests to DDR on the chip’s AXI fabric.
The key to finding the Goldilocks amount of memory – not too small and not too much – is twofold:
Solving the Memory Challenge - Smartly
Quadric has written extensively on techniques that analyze data usage across large swathes of an ML graph to ease memory bottlenecks. Our blog on advanced operator fusion – Fusion In Local Memory (FILM) – illustrates these techniques.
Additionally, the extensive suite of system simulation capability that accompanies the Chimera core provides a rich set of data that helps the SoC designer understand code and memory behavior. And the ability of the Chimera Graph Compiler to smartly schedule prefetching of data provides tremendous resiliency to aberrant system response times, even when a Chimera GPNPU is configured with relatively small local memories.
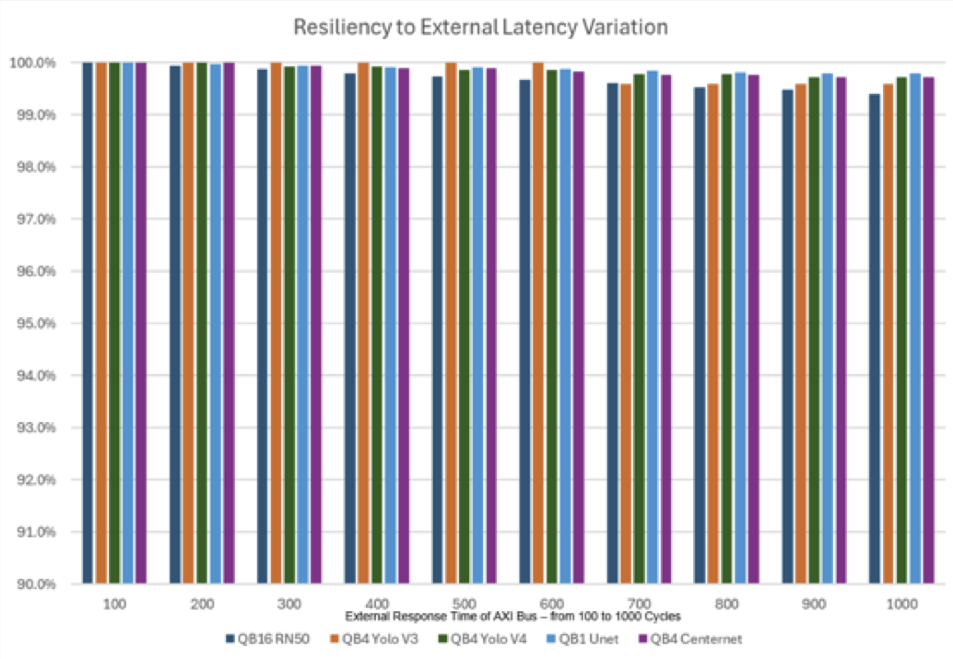
Quadric Chimera GPNPUs can be configured with a local buffer memory ranging from 1 MB to 32 MB, depending on system requirements. Some chip architects assume that a fully C++ programmable processor like the Chimera core needs “large” local memories to deliver good performance. But as the chart below shows, smartly managing local memory with a code-driven graph compilation technology delivers excellent resiliency to system resource contention with even very small local memory configuration.
For this analysis we sampled five different ML networks (ResNet50, two Yolo variants, UNet and CenterNet) across all three Chimera core sizes (1 TOP, 4 TOP, 16 TOP). In all scenarios we modeled core performance with a relatively small 4 MB of local SRAM (called L2 memory in our architecture) and assumed peak AXI system bandwidth to DDR memory of 32 GB/sec (an LPDDR4 or LPDDR5 connection).
Thanks to extensive FILM region optimization and smart data prefetching, all five scenarios show remarkable tolerance of sluggish system response, as the Chimera core performance degrades less than 1% even when average DDR response time is 10X worse than the system ideal of 100 cycles (1000 cycles instead of 100).
The bottom line: Don’t agonize over how much or how little memory to choose. Don’t squeeze memory and simply hope for the best. Choose an ML solution with the kind of programmability, modeling capability, and smart memory management that Quadric offers, and instead of agony, you’ll know you made the right resource choices before you tapeout, and you’ll be saying “Thanks for the memories!” See for yourself at www.quadric.io
© Copyright 2025 Quadric All Rights Reserved Privacy Policy