
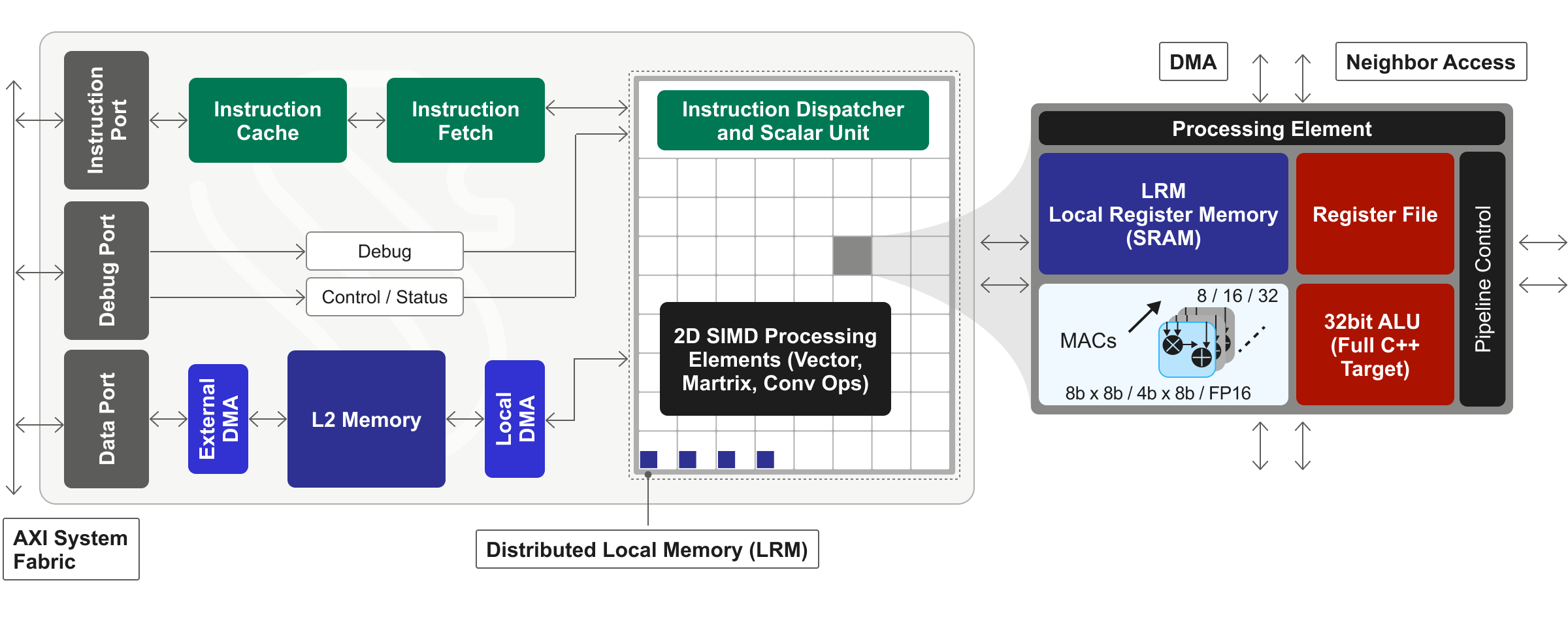
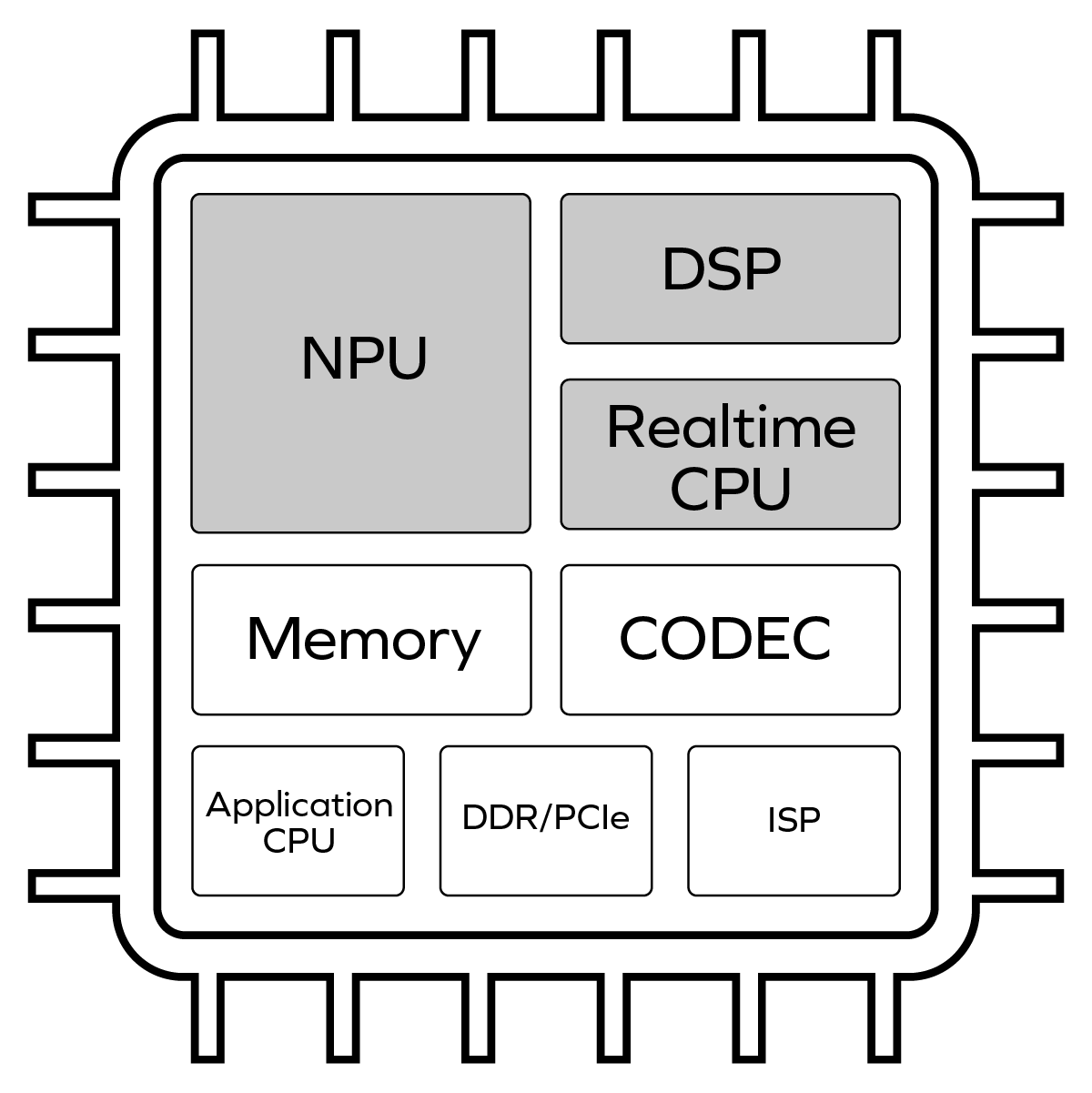
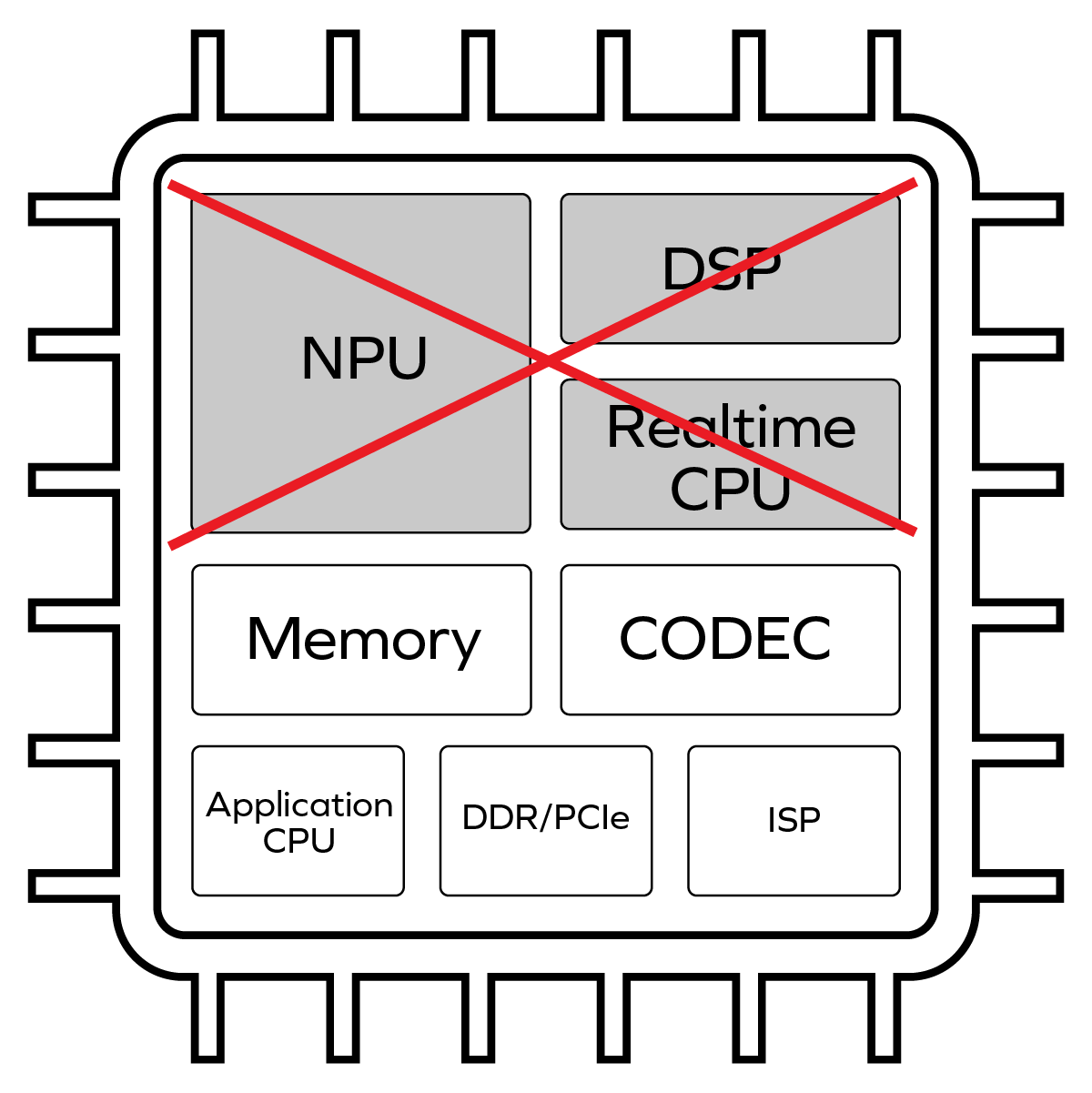
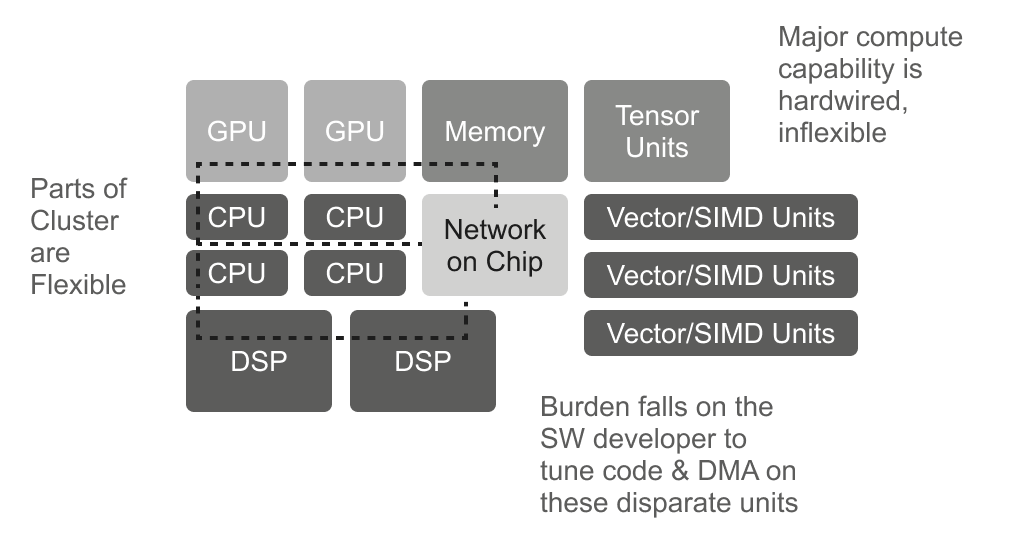
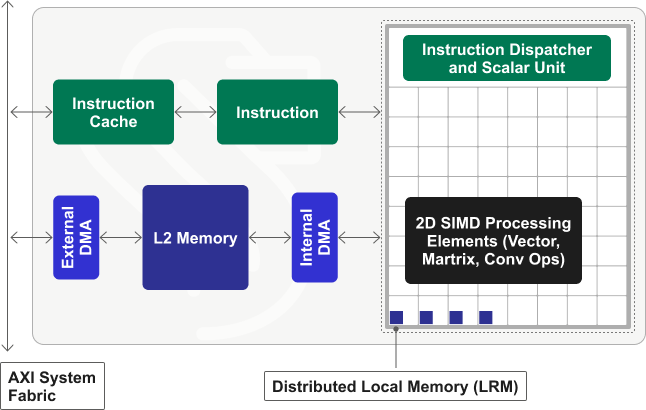
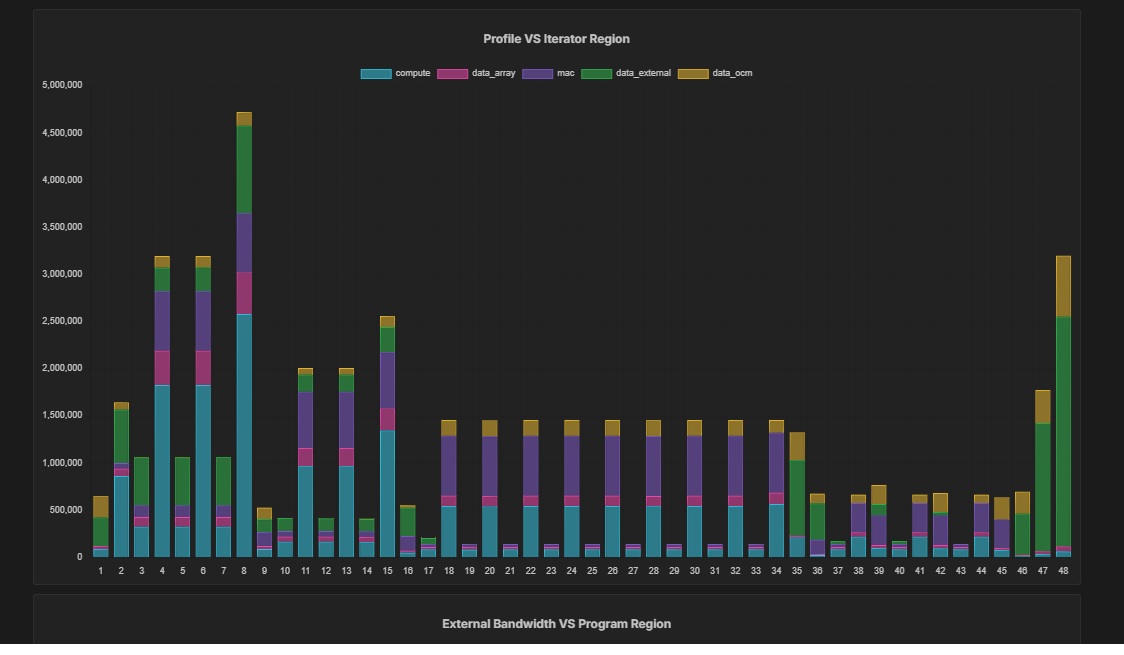
The term “model zoo” first gained prominence in the world of Artificial Intelligence/Machine Learning (AI/ML) beginning in the 2016-2017 timeframe. Originally used to describe open-source public repositories of working AI models — the most prominent […]